Deck 4: Descriptive Data Mining
ملء الشاشة (f)
سؤال
سؤال
سؤال
سؤال
سؤال
سؤال
سؤال
سؤال
سؤال
سؤال
سؤال
سؤال
سؤال
سؤال
سؤال
سؤال
سؤال
سؤال
سؤال
سؤال
سؤال
سؤال
سؤال
سؤال
سؤال
سؤال
سؤال
سؤال
سؤال
سؤال
سؤال
سؤال
سؤال
سؤال
سؤال
سؤال
سؤال
سؤال
سؤال
سؤال
سؤال
سؤال
سؤال
سؤال
سؤال
سؤال
سؤال
سؤال
سؤال
A retailer is interested in analyzing the shopping trend of men concerning the items: Shirts, pants, Jeans, t-shirts, Shoes, and Belts. A sample of 50 male customers is selected and the data are given below.
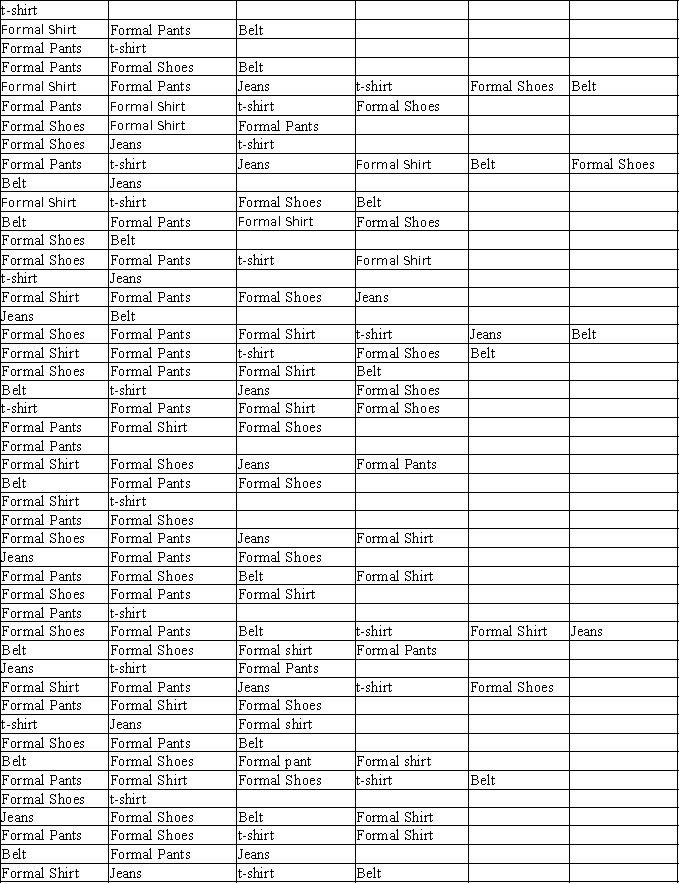
a. Using a minimum support of 20 transactions and a minimum confidence of 50 percent, use XLMiner to generate a
list of association rules. How many rules satisfy this criterion?
b. Using the list of rules from part a, consider the rule with the largest lift ratio. Interpret what this rule is saying
about the relationship between the antecedent item set and consequent item set.
c. Interpret the support count of the item set composed of the all the items involved in the rule with the largest
lift ratio.
d. Interpret the confidence of the rule with the largest lift ratio.
e. Interpret the lift ratio of the rule with the largest lift ratio.
a. Using a minimum support of 20 transactions and a minimum confidence of 50 percent, use XLMiner to generate a
list of association rules. How many rules satisfy this criterion?
b. Using the list of rules from part a, consider the rule with the largest lift ratio. Interpret what this rule is saying
about the relationship between the antecedent item set and consequent item set.
c. Interpret the support count of the item set composed of the all the items involved in the rule with the largest
lift ratio.
d. Interpret the confidence of the rule with the largest lift ratio.
e. Interpret the lift ratio of the rule with the largest lift ratio.
سؤال
سؤال
سؤال
سؤال
سؤال
سؤال
سؤال

فتح الحزمة
قم بالتسجيل لفتح البطاقات في هذه المجموعة!
Unlock Deck
Unlock Deck
1/56
العب
ملء الشاشة (f)
Deck 4: Descriptive Data Mining
1
Which is NOT a primary option for addressing missing data?
A)To discard observations with any missing values
B)To discard any variable with missing values
C)To fill in missing entries with estimated values
D)To generate random data to replace the missing values
A)To discard observations with any missing values
B)To discard any variable with missing values
C)To fill in missing entries with estimated values
D)To generate random data to replace the missing values
To generate random data to replace the missing values
2
In preparing categorical variables for analysis, it is usually best to
A)convert the categories to numeric representations.
B)convert the categories to binary, dummy variables.
C)combine as many categories as possible.
D)let them remain categorical.
A)convert the categories to numeric representations.
B)convert the categories to binary, dummy variables.
C)combine as many categories as possible.
D)let them remain categorical.
convert the categories to binary, dummy variables.
3
Observation refers to the
A)estimated continuous outcome variable.
B)set of recorded values of variables associated with a single entity.
C)goal of predicting a categorical outcome based on a set of variables.
D)mean of all variable values associated with one particular entity.
A)estimated continuous outcome variable.
B)set of recorded values of variables associated with a single entity.
C)goal of predicting a categorical outcome based on a set of variables.
D)mean of all variable values associated with one particular entity.
set of recorded values of variables associated with a single entity.
4
Which of the following reasons contributes to the increase in the use of data-mining techniques in business?
A)The lack of methods to electronically track data
B)The dearth of information to analyze and interpret
C)The ability to electronically warehouse data
D)The ability to manually analyze all the data
A)The lack of methods to electronically track data
B)The dearth of information to analyze and interpret
C)The ability to electronically warehouse data
D)The ability to manually analyze all the data
فتح الحزمة
افتح القفل للوصول البطاقات البالغ عددها 56 في هذه المجموعة.
فتح الحزمة
k this deck
5
In which of the following data-mining process steps is the data manipulated to make it suitable for formal modeling?
A)Data sampling
B)Data preparation
C)Model construction
D)Model assessment
A)Data sampling
B)Data preparation
C)Model construction
D)Model assessment
فتح الحزمة
افتح القفل للوصول البطاقات البالغ عددها 56 في هذه المجموعة.
فتح الحزمة
k this deck
6
__________________ is a measure of calculating dissimilarity between clusters by considering only the two most dissimilar observations in the two clusters.
A)Single linkage
B)Complete linkage
C)Average linkage
D)Average group linkage
A)Single linkage
B)Complete linkage
C)Average linkage
D)Average group linkage
فتح الحزمة
افتح القفل للوصول البطاقات البالغ عددها 56 في هذه المجموعة.
فتح الحزمة
k this deck
7
Single linkage is a measure of calculating dissimilarity between clusters by
A)considering only the two most dissimilar observations in the two clusters.
B)computing the average dissimilarity between every pair of observations between the two clusters.
C)considering only the two most similar observations in the two clusters.
D)considering the distance between the cluster centroids.
A)considering only the two most dissimilar observations in the two clusters.
B)computing the average dissimilarity between every pair of observations between the two clusters.
C)considering only the two most similar observations in the two clusters.
D)considering the distance between the cluster centroids.
فتح الحزمة
افتح القفل للوصول البطاقات البالغ عددها 56 في هذه المجموعة.
فتح الحزمة
k this deck
8
The data preparation technique used in market segmentation to divide consumers into different homogeneous groups is called
A)data visualization.
B)cluster analysis.
C)market analysis.
D)supervised learning.
A)data visualization.
B)cluster analysis.
C)market analysis.
D)supervised learning.
فتح الحزمة
افتح القفل للوصول البطاقات البالغ عددها 56 في هذه المجموعة.
فتح الحزمة
k this deck
9
Which of the following is true of Euclidean distances?
A)It is used to measure dissimilarity between categorical variable observations.
B)It is not affected by the scale on which variables are measured.
C)It increases with the increase in similarity between variable values.
D)It is commonly used as a method of measuring dissimilarity between quantitative observations.
A)It is used to measure dissimilarity between categorical variable observations.
B)It is not affected by the scale on which variables are measured.
C)It increases with the increase in similarity between variable values.
D)It is commonly used as a method of measuring dissimilarity between quantitative observations.
فتح الحزمة
افتح القفل للوصول البطاقات البالغ عددها 56 في هذه المجموعة.
فتح الحزمة
k this deck
10
If a model's implications depend on the inclusion or exclusion of outliers, one should spend additional time to track down
A)the cause of the outliers.
B)the missing values.
C)a better estimation of the outliers.
D)another source of data.
A)the cause of the outliers.
B)the missing values.
C)a better estimation of the outliers.
D)another source of data.
فتح الحزمة
افتح القفل للوصول البطاقات البالغ عددها 56 في هذه المجموعة.
فتح الحزمة
k this deck
11
k-means clustering is the process of
A)agglomerating observations into a series of nested groups based on a measure of similarity.
B)organizing observations into distinct groups based on a measure of similarity.
C)reducing the number of variables to consider in data-mining.
D)estimating the value of a continuous outcome variable.
A)agglomerating observations into a series of nested groups based on a measure of similarity.
B)organizing observations into distinct groups based on a measure of similarity.
C)reducing the number of variables to consider in data-mining.
D)estimating the value of a continuous outcome variable.
فتح الحزمة
افتح القفل للوصول البطاقات البالغ عددها 56 في هذه المجموعة.
فتح الحزمة
k this deck
12
The goal of ___________________ is to use the variable values to identify relationships between observations.
A)unsupervised learning
B)data mining
C)McQuitty's method
D)Ward's method
A)unsupervised learning
B)data mining
C)McQuitty's method
D)Ward's method
فتح الحزمة
افتح القفل للوصول البطاقات البالغ عددها 56 في هذه المجموعة.
فتح الحزمة
k this deck
13
Suppose we had a data set of from a call center where customers were asked to choose between the following three options:hear account information, billing questions, and customer service. Using the given order of the three options, and using 0-1 dummy variables to encode the categorical variables, which of the following combinations would yield an entry "customer service"?
A)000
B)100
C)010
D)001
A)000
B)100
C)010
D)001
فتح الحزمة
افتح القفل للوصول البطاقات البالغ عددها 56 في هذه المجموعة.
فتح الحزمة
k this deck
14
Euclidean distance can be used to calculate the dissimilarity between two observations. Let u = (25, $350) correspond to a 25-year old customer that spent $350 at Store A in the previous fiscal year. Let v = (53, $420) correspond to a 53-year old customer that spent $4,100 at Store A in the previous fiscal year. Calculate the dissimilarity between these two observations using Euclidean distance.
A)66.21
B)72.28
C)75.39
D)88.57
A)66.21
B)72.28
C)75.39
D)88.57
فتح الحزمة
افتح القفل للوصول البطاقات البالغ عددها 56 في هذه المجموعة.
فتح الحزمة
k this deck
15
Imputing values is valid only if the variable values are We may replace missing values with the variable's mode, mean, or median, but only if the variable values are
A)not missing at random (MNAR).
B)missing at random (MAR).
C)missing completely at random (MCAR).
D)Classification and Regression Trees (CART).
A)not missing at random (MNAR).
B)missing at random (MAR).
C)missing completely at random (MCAR).
D)Classification and Regression Trees (CART).
فتح الحزمة
افتح القفل للوصول البطاقات البالغ عددها 56 في هذه المجموعة.
فتح الحزمة
k this deck
16
_______________ approaches are designed to describe patterns and relationships in large data sets with many observations of many variables.
A)Data mining
B)Unsupervised learning
C)Dimension reduction
D)Data sampling
A)Data mining
B)Unsupervised learning
C)Dimension reduction
D)Data sampling
فتح الحزمة
افتح القفل للوصول البطاقات البالغ عددها 56 في هذه المجموعة.
فتح الحزمة
k this deck
17
Data preparation includes all of the following except which task?
A)calculating the confidence ratio for all association rules
B)treating missing data
C)identifying erroneous data and outliers
D)defining the appropriate way to represent variables
A)calculating the confidence ratio for all association rules
B)treating missing data
C)identifying erroneous data and outliers
D)defining the appropriate way to represent variables
فتح الحزمة
افتح القفل للوصول البطاقات البالغ عددها 56 في هذه المجموعة.
فتح الحزمة
k this deck
18
If the Euclidean distance were to be represented in a right triangle, which of the following would be considered the distance between two observations of a cluster?
A)the short leg
B)the long leg
C)the hypotenuse
D)Eudlidean distance is not related to right triangles.
A)the short leg
B)the long leg
C)the hypotenuse
D)Eudlidean distance is not related to right triangles.
فتح الحزمة
افتح القفل للوصول البطاقات البالغ عددها 56 في هذه المجموعة.
فتح الحزمة
k this deck
19
The process of eliminating variables from formal analysis without losing any crucial information is called
A)dimension reduction.
B)data sampling.
C)data reduction.
D)aggregation.
A)dimension reduction.
B)data sampling.
C)data reduction.
D)aggregation.
فتح الحزمة
افتح القفل للوصول البطاقات البالغ عددها 56 في هذه المجموعة.
فتح الحزمة
k this deck
20
Jaccard's coefficient is different from the matching coefficient in that the former
A)measures overlap while the latter measures dissimilarity.
B)does not count matching zero entries while the latter does.
C)deals with categorical variable while the latter deals with continuous variables.
D)is affected by the scale used to measure variables while the latter is not.
A)measures overlap while the latter measures dissimilarity.
B)does not count matching zero entries while the latter does.
C)deals with categorical variable while the latter deals with continuous variables.
D)is affected by the scale used to measure variables while the latter is not.
فتح الحزمة
افتح القفل للوصول البطاقات البالغ عددها 56 في هذه المجموعة.
فتح الحزمة
k this deck
21
A tree diagram used to illustrate the sequence of nested clusters produced by hierarchical clustering is known as a
A)dendrogram.
B)scatter chart.
C)decile-wise lift chart.
D)cumulative lift tree.
A)dendrogram.
B)scatter chart.
C)decile-wise lift chart.
D)cumulative lift tree.
فتح الحزمة
افتح القفل للوصول البطاقات البالغ عددها 56 في هذه المجموعة.
فتح الحزمة
k this deck
22
Euclidean distance can be used to measure the distance between________________ in cluster analysis.
A)objects
B)clusters
C)observations
D)ward
A)objects
B)clusters
C)observations
D)ward
فتح الحزمة
افتح القفل للوصول البطاقات البالغ عددها 56 في هذه المجموعة.
فتح الحزمة
k this deck
23
Suppose the dissimilarity between clusters A and B has the value 24 and the dissimilarity between cluster B and C has the value 12. Use McQuitty's method to determine the dissimilarity of clusters A and B.
A)12
B)18
C)24
D)36
A)12
B)18
C)24
D)36
فتح الحزمة
افتح القفل للوصول البطاقات البالغ عددها 56 في هذه المجموعة.
فتح الحزمة
k this deck
24
In which of the following scenarios would it be appropriate to use hierarchical clustering?
A)When the number of observations in the dataset is relatively high.
B)When it is not necessary to know the nesting of clusters.
C)When the number of clusters is known beforehand.
D)When binary or ordinal data needs to be clustered.
A)When the number of observations in the dataset is relatively high.
B)When it is not necessary to know the nesting of clusters.
C)When the number of clusters is known beforehand.
D)When binary or ordinal data needs to be clustered.
فتح الحزمة
افتح القفل للوصول البطاقات البالغ عددها 56 في هذه المجموعة.
فتح الحزمة
k this deck
25
The endpoint of a k-means clustering algorithm occurs when
A)Euclidean distance between clusters is minimized.
B)Euclidean distance between observations in a cluster is maximized.
C)no further changes are observed in cluster structure and number.
D)all of the observations are encompassed within a single large cluster with mean k.
A)Euclidean distance between clusters is minimized.
B)Euclidean distance between observations in a cluster is maximized.
C)no further changes are observed in cluster structure and number.
D)all of the observations are encompassed within a single large cluster with mean k.
فتح الحزمة
افتح القفل للوصول البطاقات البالغ عددها 56 في هذه المجموعة.
فتح الحزمة
k this deck
26
When clustering only by dummy variables that represent categorical variables, the simplest measure of similarity between two observations is called the
A)matching coefficient.
B)Jaccard's coefficient.
C)Euclidean distance.
D)antecedent.
A)matching coefficient.
B)Jaccard's coefficient.
C)Euclidean distance.
D)antecedent.
فتح الحزمة
افتح القفل للوصول البطاقات البالغ عددها 56 في هذه المجموعة.
فتح الحزمة
k this deck
27
The strength of a cluster can be measured by comparing the average distance in a cluster to the distance between cluster centroids. One rule of thumb is that the ratio for between-cluster distance to within-cluster distance should exceed what value for useful clusters?
A)0.5
B)1
C)1.5
D)2
A)0.5
B)1
C)1.5
D)2
فتح الحزمة
افتح القفل للوصول البطاقات البالغ عددها 56 في هذه المجموعة.
فتح الحزمة
k this deck
28
A method for modifying variables that reduces bias prior to cluster analysis is
A)standardization.
B)weighting.
C)removing outliers.
D)randomizing.
A)standardization.
B)weighting.
C)removing outliers.
D)randomizing.
فتح الحزمة
افتح القفل للوصول البطاقات البالغ عددها 56 في هذه المجموعة.
فتح الحزمة
k this deck
29
________________ is a measure that computes the dissimilarity between a cluster AB and a cluster C by averaging the distance between A and C and the distance between B and C.
A)Ward's method
B)Jaccard's coefficient
C)McQuitty's method
D)None of these.
A)Ward's method
B)Jaccard's coefficient
C)McQuitty's method
D)None of these.
فتح الحزمة
افتح القفل للوصول البطاقات البالغ عددها 56 في هذه المجموعة.
فتح الحزمة
k this deck
30
A ___________ refers to the number of times a collection of items occur together in a transaction data set.
A)consequent
B)validation count
C)support count
D)antecedent
A)consequent
B)validation count
C)support count
D)antecedent
فتح الحزمة
افتح القفل للوصول البطاقات البالغ عددها 56 في هذه المجموعة.
فتح الحزمة
k this deck
31
Single linkage can be used to measure the distance between clusters that are the _______________ in cluster analysis.
A)most similar
B)most different
C)farthest apart
D)closest
A)most similar
B)most different
C)farthest apart
D)closest
فتح الحزمة
افتح القفل للوصول البطاقات البالغ عددها 56 في هذه المجموعة.
فتح الحزمة
k this deck
32
Complete linkage can be used to measure the distance between clusters that are the _________________ in cluster analysis.
A)most similar
B)most different
C)farthest apart
D)closest
A)most similar
B)most different
C)farthest apart
D)closest
فتح الحزمة
افتح القفل للوصول البطاقات البالغ عددها 56 في هذه المجموعة.
فتح الحزمة
k this deck
33
In k-means clustering, k represents the
A)number of variables.
B)number of clusters.
C)number of observations in a cluster.
D)mean of the cluster.
A)number of variables.
B)number of clusters.
C)number of observations in a cluster.
D)mean of the cluster.
فتح الحزمة
افتح القفل للوصول البطاقات البالغ عددها 56 في هذه المجموعة.
فتح الحزمة
k this deck
34
___________________ can be used to partition observations in a manner to obtain clusters with the least amount of information loss due to the aggregation.
A)Single linkage
B)Ward's method
C)Average group linkage
D)Dendrogram
A)Single linkage
B)Ward's method
C)Average group linkage
D)Dendrogram
فتح الحزمة
افتح القفل للوصول البطاقات البالغ عددها 56 في هذه المجموعة.
فتح الحزمة
k this deck
35
Heirarchial clusting using ____________ results in a sequence of aggregated clusters that minimizes the loss of information between the individual observation level and the cluster level
A)McQuitty's method
B)centroid linkage
C)median linkage
D)Ward's method
A)McQuitty's method
B)centroid linkage
C)median linkage
D)Ward's method
فتح الحزمة
افتح القفل للوصول البطاقات البالغ عددها 56 في هذه المجموعة.
فتح الحزمة
k this deck
36
____________________ measures cluster similarity by calculating the distance between the centroids of the two clusters.
A)Single linkage
B)Complete linkage
C)Average linkage
D)Cendroid linkage
A)Single linkage
B)Complete linkage
C)Average linkage
D)Cendroid linkage
فتح الحزمة
افتح القفل للوصول البطاقات البالغ عددها 56 في هذه المجموعة.
فتح الحزمة
k this deck
37
A cluster's _____________ can be measured by the difference between the distance value at which a cluster is originally formed and the distance value at which it is merged with another cluster in a dendrogram.
A)dimension
B)affordability
C)durability
D)span
A)dimension
B)affordability
C)durability
D)span
فتح الحزمة
افتح القفل للوصول البطاقات البالغ عددها 56 في هذه المجموعة.
فتح الحزمة
k this deck
38
Average linkage is a measure of calculating dissimilarity between two clusters by
A)finding the distance between the two most dissimilar observations in the two clusters.
B)computing the average distance between every pair of observations between two clusters.
C)finding the distance between the two closest observations in the two clusters.
D)computing the distance between the cluster centroids.
A)finding the distance between the two most dissimilar observations in the two clusters.
B)computing the average distance between every pair of observations between two clusters.
C)finding the distance between the two closest observations in the two clusters.
D)computing the distance between the cluster centroids.
فتح الحزمة
افتح القفل للوصول البطاقات البالغ عددها 56 في هذه المجموعة.
فتح الحزمة
k this deck
39
Complete linkage can be used to measure the distance between _________ in cluster analysis.
A)objects
B)clusters
C)observations
D)wards
A)objects
B)clusters
C)observations
D)wards
فتح الحزمة
افتح القفل للوصول البطاقات البالغ عددها 56 في هذه المجموعة.
فتح الحزمة
k this deck
40
An analysis of items frequently co-occurring in transactions is known as
A)market segmentation.
B)market basket analysis.
C)regression analysis.
D)cluster analysis.
A)market segmentation.
B)market basket analysis.
C)regression analysis.
D)cluster analysis.
فتح الحزمة
افتح القفل للوصول البطاقات البالغ عددها 56 في هذه المجموعة.
فتح الحزمة
k this deck
41
Using the data given, apply hierarchical clustering with 10 clusters using LandValue ($), BuildingValue ($), Acres, Age, and Price ($) as variables. Be sure to Normalize input data in Step 2 of the XLMiner Hierarchical Clustering procedure. Use Ward's method as the clustering method.
a. Use a PivotTable on the data in the HC_Clusters1 worksheet to compute the cluster centers for the clusters in the
hierarchical clustering.
b. Identify the cluster with the largest average price. Using all the variables, how would you characterize this cluster?
c. Identify the smallest cluster.
a. Use a PivotTable on the data in the HC_Clusters1 worksheet to compute the cluster centers for the clusters in the
hierarchical clustering.
b. Identify the cluster with the largest average price. Using all the variables, how would you characterize this cluster?
c. Identify the smallest cluster.
فتح الحزمة
افتح القفل للوصول البطاقات البالغ عددها 56 في هذه المجموعة.
فتح الحزمة
k this deck
42
Using the data given, apply k-means clustering using Price ($) as the variable with k = 3. Be sure to Normalize input data, and specify 50 iterations and 10 random starts in Step 2 of the XLMiner k-Means Clustering procedure. Then create one distinct data set for each of the three resulting clusters of price.
a. For the observations composing the cluster with low home price, apply hierarchical clustering with Ward's method to form three clusters using Acres and Age as variables. Be sure to Normalize input data in Step 2 of the XLMiner Hierarchical Clustering procedure. Using a PivotTable on the data in HC_Clusters1, report the characteristics of each cluster.
b. For the observations composing the cluster with medium home price, apply hierarchical clustering with Ward's method to form three clusters using Acres and Age as variables. Be sure to Normalize input data in Step 2 of the XLMiner Hierarchical Clustering procedure. Using a PivotTable on the data in HC_Clusters1, report the characteristics of each cluster.
c. Comment on the cluster with high home price.
a. For the observations composing the cluster with low home price, apply hierarchical clustering with Ward's method to form three clusters using Acres and Age as variables. Be sure to Normalize input data in Step 2 of the XLMiner Hierarchical Clustering procedure. Using a PivotTable on the data in HC_Clusters1, report the characteristics of each cluster.
b. For the observations composing the cluster with medium home price, apply hierarchical clustering with Ward's method to form three clusters using Acres and Age as variables. Be sure to Normalize input data in Step 2 of the XLMiner Hierarchical Clustering procedure. Using a PivotTable on the data in HC_Clusters1, report the characteristics of each cluster.
c. Comment on the cluster with high home price.
فتح الحزمة
افتح القفل للوصول البطاقات البالغ عددها 56 في هذه المجموعة.
فتح الحزمة
k this deck
43
Platinum Gym has 10,000 gyms members out of which 1500 memberships included Unlimited Fitness Training and use of the tanning salon, and out of which 750 included Unlimited Hydromassage. If the Fitness Training are considered A, the use of the tanning salon are considered B, and the Hydromassage are considered C, then the associate rule for these sales become "If A and B are purchased, then C is also purchased." Calculate the confidence level.
فتح الحزمة
افتح القفل للوصول البطاقات البالغ عددها 56 في هذه المجموعة.
فتح الحزمة
k this deck
44
Suppose that the confidence of an association rule is 0.75 and the total number of transactions is 250. How many of those transactions support the consequent if the lift ratio is 1.875?
A)100
B)125
C)150
D)175
A)100
B)125
C)150
D)175
فتح الحزمة
افتح القفل للوصول البطاقات البالغ عددها 56 في هذه المجموعة.
فتح الحزمة
k this deck
45
To identify patterns across transactions, we can use
A)association rules.
B)complete linkage.
C)centroid linkage.
D)k-means.
A)association rules.
B)complete linkage.
C)centroid linkage.
D)k-means.
فتح الحزمة
افتح القفل للوصول البطاقات البالغ عددها 56 في هذه المجموعة.
فتح الحزمة
k this deck
46
Which statement is true of an association rule?
A)It is ultimately judged on how actionable it is and how well it explains the relationship between item sets.
B)It is a data reduction technique that reduces large information into smaller homogeneous groups.
C)It uses analytic models to describe the relationship between metrics that drive business performance.
D)It seeks to classify a categorical outcome into two or more categories.
A)It is ultimately judged on how actionable it is and how well it explains the relationship between item sets.
B)It is a data reduction technique that reduces large information into smaller homogeneous groups.
C)It uses analytic models to describe the relationship between metrics that drive business performance.
D)It seeks to classify a categorical outcome into two or more categories.
فتح الحزمة
افتح القفل للوصول البطاقات البالغ عددها 56 في هذه المجموعة.
فتح الحزمة
k this deck
47
The strength of the association rule is known as ____________ and is calculated as the ratio of the confidence of an association rule to the benchmark confidence.
A)lift
B)antecedent
C)support count
D)consequent
A)lift
B)antecedent
C)support count
D)consequent
فتح الحزمة
افتح القفل للوصول البطاقات البالغ عددها 56 في هذه المجموعة.
فتح الحزمة
k this deck
48
___________________uses the averaging concept of cluster centroids to define between-cluster similarity.
فتح الحزمة
افتح القفل للوصول البطاقات البالغ عددها 56 في هذه المجموعة.
فتح الحزمة
k this deck
49
A retailer is interested in analyzing the shopping trend of men concerning the items: Shirts, pants, Jeans, t-shirts, Shoes, and Belts. A sample of 50 male customers is selected and the data are given below.
a. Using a minimum support of 20 transactions and a minimum confidence of 50 percent, use XLMiner to generate a
list of association rules. How many rules satisfy this criterion?
b. Using the list of rules from part a, consider the rule with the largest lift ratio. Interpret what this rule is saying
about the relationship between the antecedent item set and consequent item set.
c. Interpret the support count of the item set composed of the all the items involved in the rule with the largest
lift ratio.
d. Interpret the confidence of the rule with the largest lift ratio.
e. Interpret the lift ratio of the rule with the largest lift ratio.
a. Using a minimum support of 20 transactions and a minimum confidence of 50 percent, use XLMiner to generate a
list of association rules. How many rules satisfy this criterion?
b. Using the list of rules from part a, consider the rule with the largest lift ratio. Interpret what this rule is saying
about the relationship between the antecedent item set and consequent item set.
c. Interpret the support count of the item set composed of the all the items involved in the rule with the largest
lift ratio.
d. Interpret the confidence of the rule with the largest lift ratio.
e. Interpret the lift ratio of the rule with the largest lift ratio.
فتح الحزمة
افتح القفل للوصول البطاقات البالغ عددها 56 في هذه المجموعة.
فتح الحزمة
k this deck
50
Using the data given, apply hierarchical clustering with 5 clusters using Wait Time (min), Purchase Amount ($),
Customer Age, and Customer Satisfaction Rating as variables. Be sure to Normalize input data in Step 2 of the
XLMiner Hierarchical Clustering procedure. Use Ward's method as the clustering method.
a. Use a PivotTable on the data in the HC_Clusters1 worksheet to compute the cluster centers for the five clusters
in the hierarchical clustering.
b. Identify the cluster with the largest average waiting time. Using all the variables, how would you characterize
this cluster?
c. Identify the smallest cluster.
d. By examining the dendrogram on the HC_Dendrogram worksheet (as well as the sequence of clustering stages
in HC_Output1), what number of clusters seems to be the most natural fit based on the distance?
Customer Age, and Customer Satisfaction Rating as variables. Be sure to Normalize input data in Step 2 of the
XLMiner Hierarchical Clustering procedure. Use Ward's method as the clustering method.
a. Use a PivotTable on the data in the HC_Clusters1 worksheet to compute the cluster centers for the five clusters
in the hierarchical clustering.
b. Identify the cluster with the largest average waiting time. Using all the variables, how would you characterize
this cluster?
c. Identify the smallest cluster.
d. By examining the dendrogram on the HC_Dendrogram worksheet (as well as the sequence of clustering stages
in HC_Output1), what number of clusters seems to be the most natural fit based on the distance?
فتح الحزمة
افتح القفل للوصول البطاقات البالغ عددها 56 في هذه المجموعة.
فتح الحزمة
k this deck
51
Using the data given, apply k-means clustering using Wait time (min) as the variable with k = 3. Be sure to Normalize input data, and specify 50 iterations and 10 random starts in Step 2 of the XLMiner k-Means Clustering procedure. Then create one distinct data set for each of the three resulting clusters for waiting time.
a. For the observations composing the cluster which has the low waiting time, apply hierarchical clustering with Ward's method to form two clusters using Purchase Amount, Customer Age, and Customer Satisfaction Rating as variables. Be sure to Normalize input data in Step 2 of the XLMiner Hierarchical Clustering procedure. Using a PivotTable on the data in HC_Clusters, report the characteristics of each cluster.
b. For the observations composing the cluster which has the medium waiting time, apply hierarchical clustering with Ward's method to form three clusters using Purchase Amount, Customer Age, and Customer Satisfaction Rating as variables. Be sure to Normalize input data in Step 2 of the XLMiner Hierarchical Clustering procedure. Using a PivotTable on the data in HC_Clusters, report the characteristics of each cluster.
c. For the observations composing the cluster which has the high waiting time, apply hierarchical clustering with Ward's method to form two clusters using Purchase Amount, Customer Age, and Customer Satisfaction Rating as variables. Be sure to Normalize input data in Step 2 of the XLMiner Hierarchical Clustering procedure. Using a PivotTable on the data in HC_Clusters, report the characteristics of each cluster.
a. For the observations composing the cluster which has the low waiting time, apply hierarchical clustering with Ward's method to form two clusters using Purchase Amount, Customer Age, and Customer Satisfaction Rating as variables. Be sure to Normalize input data in Step 2 of the XLMiner Hierarchical Clustering procedure. Using a PivotTable on the data in HC_Clusters, report the characteristics of each cluster.
b. For the observations composing the cluster which has the medium waiting time, apply hierarchical clustering with Ward's method to form three clusters using Purchase Amount, Customer Age, and Customer Satisfaction Rating as variables. Be sure to Normalize input data in Step 2 of the XLMiner Hierarchical Clustering procedure. Using a PivotTable on the data in HC_Clusters, report the characteristics of each cluster.
c. For the observations composing the cluster which has the high waiting time, apply hierarchical clustering with Ward's method to form two clusters using Purchase Amount, Customer Age, and Customer Satisfaction Rating as variables. Be sure to Normalize input data in Step 2 of the XLMiner Hierarchical Clustering procedure. Using a PivotTable on the data in HC_Clusters, report the characteristics of each cluster.
فتح الحزمة
افتح القفل للوصول البطاقات البالغ عددها 56 في هذه المجموعة.
فتح الحزمة
k this deck
52
Platinum Gym has 10,000 gyms members out of which 1500 memberships included Unlimited Fitness Training and use of the tanning salon, and out of which 750 included Unlimited Hydromassage. If the Fitness Training are considered A, the use of the tanning salon are considered B, and the Hydromassage are considered C, then the associate rule for these sales become, "If A and B are purchased, then C is also purchased." Given total transactions for C is 3000. Calculate the lift for this rule.
فتح الحزمة
افتح القفل للوصول البطاقات البالغ عددها 56 في هذه المجموعة.
فتح الحزمة
k this deck
53
The lift ratio of an association rule with a confidence value of 0.45 and in which the consequent occurs in 6 out of 10 cases is
A)1.40.
B)0.54.
C)1.00.
D)0.75.
A)1.40.
B)0.54.
C)1.00.
D)0.75.
فتح الحزمة
افتح القفل للوصول البطاقات البالغ عددها 56 في هذه المجموعة.
فتح الحزمة
k this deck
54
Platinum Gym has 10,000 gyms members out of which 1500 memberships included Unlimited Fitness Training and use of the tanning salon, and out of which 750 included Unlimited Hydromassage. If the Fitness Training are considered A, the use of the tanning salon are considered B, and the Hydromassage are considered C, then the associate rule for these sales become "If A and B are purchased, then C is also purchased." Given total transactions for C is 3000. Calculate benchmark confidence level.
فتح الحزمة
افتح القفل للوصول البطاقات البالغ عددها 56 في هذه المجموعة.
فتح الحزمة
k this deck
55
The __________ the lift ratio, the ____________ the association rule.
A)higher; stronger
B)higher; weaker
C)lower; stronger
D)lower; weaker
A)higher; stronger
B)higher; weaker
C)lower; stronger
D)lower; weaker
فتح الحزمة
افتح القفل للوصول البطاقات البالغ عددها 56 في هذه المجموعة.
فتح الحزمة
k this deck
56
____________________ clustering method defines the similarity between two clusters as the similarity of the pair of observations (one from each cluster) that are the most different.
فتح الحزمة
افتح القفل للوصول البطاقات البالغ عددها 56 في هذه المجموعة.
فتح الحزمة
k this deck
فتح الحزمة
افتح القفل للوصول البطاقات البالغ عددها 56 في هذه المجموعة.








