Deck 10: Data Mining
ملء الشاشة (f)
سؤال
سؤال
سؤال
Exhibit 10.2
The following questions are based on the problem description and the output below.
A college admissions officer wants to evaluate graduate school applicants based on their GMAT scores, verbal and quantitative. Students are classified as either successful (Group 1), marginally successful (Group 2) or not-successful (Group 3) in their graduate studies. The officer has data on 20 current students, 7 successful (Group 1), 6 marginally successful (Group 2) and 7 not successful (Group 3).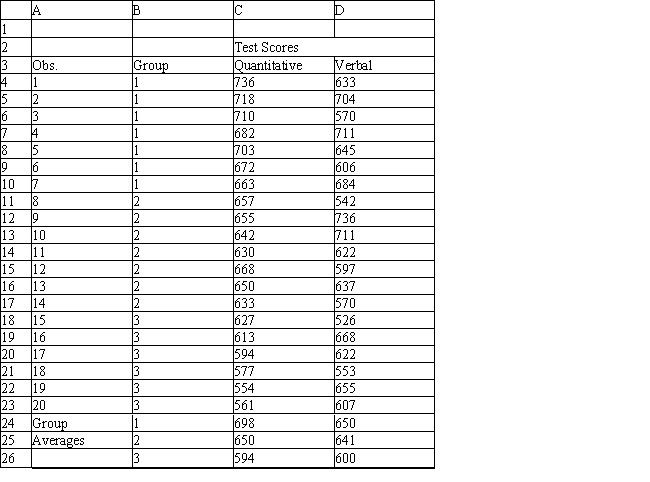


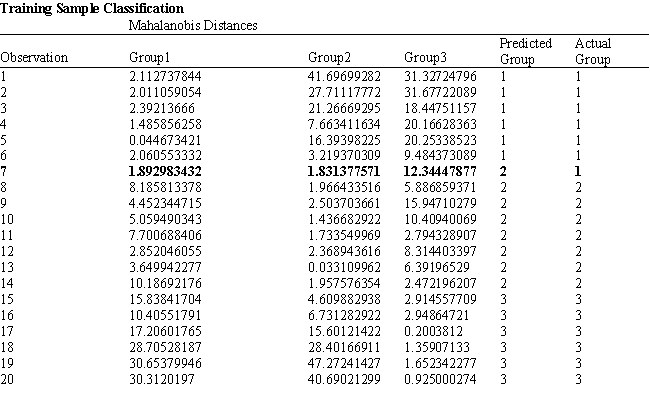

Refer to Exhibit 10.2. What is the verbal test score value of the group centroid for group 3?
A) 697.71
B) 647.86
C) 587.67
D) 605.17
The following questions are based on the problem description and the output below.
A college admissions officer wants to evaluate graduate school applicants based on their GMAT scores, verbal and quantitative. Students are classified as either successful (Group 1), marginally successful (Group 2) or not-successful (Group 3) in their graduate studies. The officer has data on 20 current students, 7 successful (Group 1), 6 marginally successful (Group 2) and 7 not successful (Group 3).
Refer to Exhibit 10.2. What is the verbal test score value of the group centroid for group 3?
A) 697.71
B) 647.86
C) 587.67
D) 605.17
سؤال
سؤال
سؤال
سؤال
سؤال
سؤال
سؤال
Exhibit 10.2
The following questions are based on the problem description and the output below.
A college admissions officer wants to evaluate graduate school applicants based on their GMAT scores, verbal and quantitative. Students are classified as either successful (Group 1), marginally successful (Group 2) or not-successful (Group 3) in their graduate studies. The officer has data on 20 current students, 7 successful (Group 1), 6 marginally successful (Group 2) and 7 not successful (Group 3).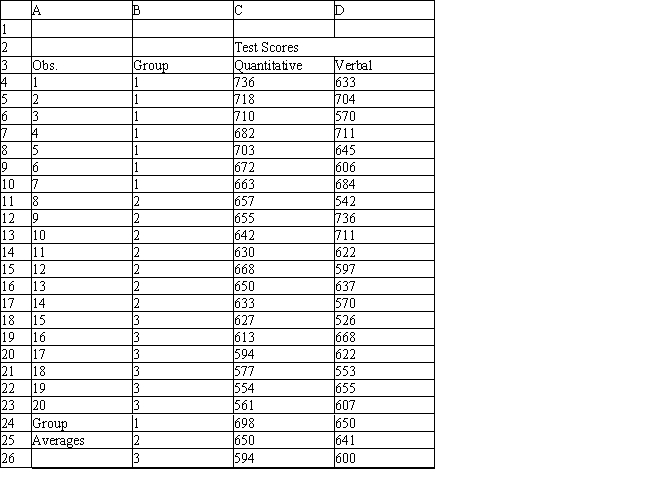


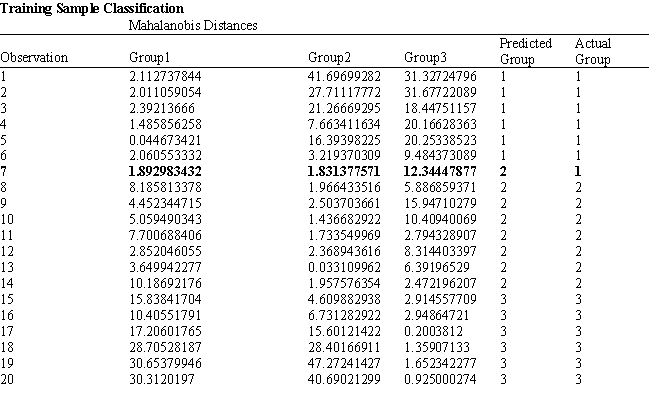

Refer to Exhibit 10.2. What is the quantitative test score value of the group centroid for group 1?
A) 697.71
B) 647.86
C) 587.67
D) 650.43
The following questions are based on the problem description and the output below.
A college admissions officer wants to evaluate graduate school applicants based on their GMAT scores, verbal and quantitative. Students are classified as either successful (Group 1), marginally successful (Group 2) or not-successful (Group 3) in their graduate studies. The officer has data on 20 current students, 7 successful (Group 1), 6 marginally successful (Group 2) and 7 not successful (Group 3).
Refer to Exhibit 10.2. What is the quantitative test score value of the group centroid for group 1?
A) 697.71
B) 647.86
C) 587.67
D) 650.43
سؤال
Exhibit 10.2
The following questions are based on the problem description and the output below.
A college admissions officer wants to evaluate graduate school applicants based on their GMAT scores, verbal and quantitative. Students are classified as either successful (Group 1), marginally successful (Group 2) or not-successful (Group 3) in their graduate studies. The officer has data on 20 current students, 7 successful (Group 1), 6 marginally successful (Group 2) and 7 not successful (Group 3).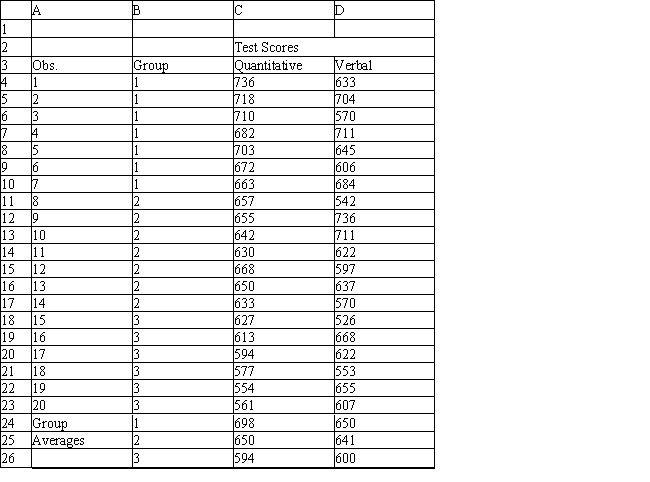


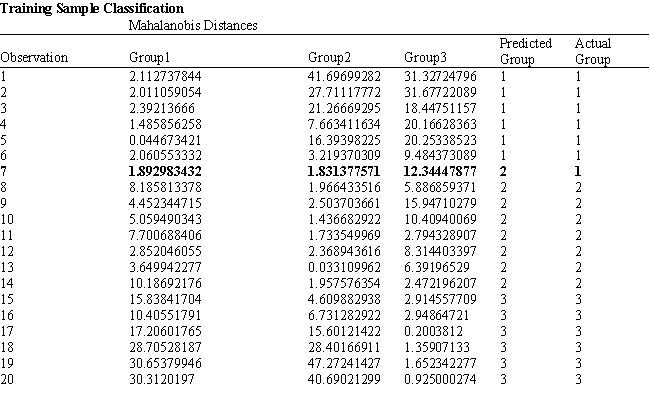

Refer to Exhibit 10.2. What percentage of observations is classified correctly?
A) 100%
B) 85.71%
C) 95%
D) 90%
The following questions are based on the problem description and the output below.
A college admissions officer wants to evaluate graduate school applicants based on their GMAT scores, verbal and quantitative. Students are classified as either successful (Group 1), marginally successful (Group 2) or not-successful (Group 3) in their graduate studies. The officer has data on 20 current students, 7 successful (Group 1), 6 marginally successful (Group 2) and 7 not successful (Group 3).
Refer to Exhibit 10.2. What percentage of observations is classified correctly?
A) 100%
B) 85.71%
C) 95%
D) 90%
سؤال
Exhibit 10.2
The following questions are based on the problem description and the output below.
A college admissions officer wants to evaluate graduate school applicants based on their GMAT scores, verbal and quantitative. Students are classified as either successful (Group 1), marginally successful (Group 2) or not-successful (Group 3) in their graduate studies. The officer has data on 20 current students, 7 successful (Group 1), 6 marginally successful (Group 2) and 7 not successful (Group 3).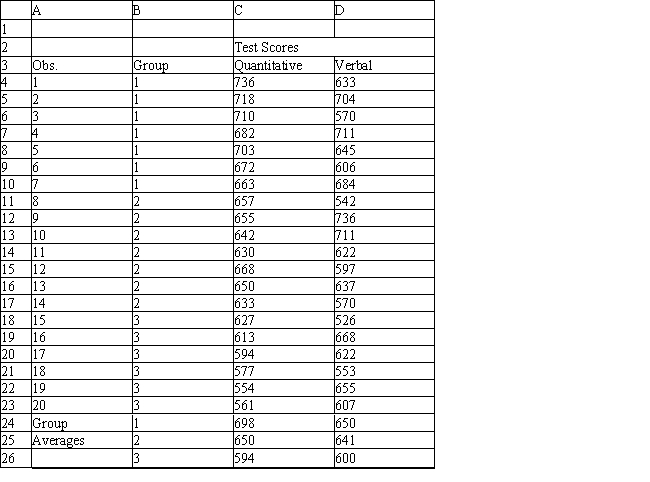


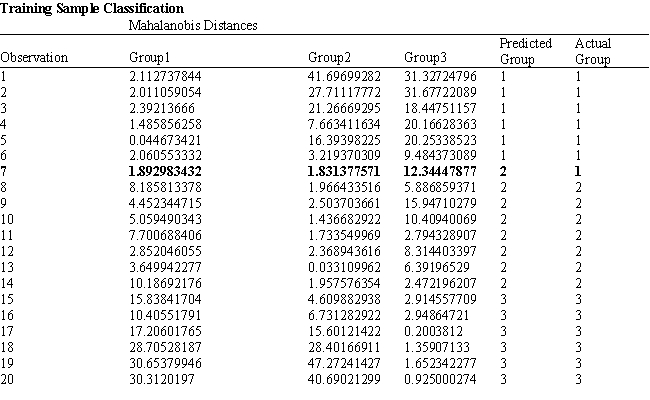

Refer to Exhibit 10.2. What number of observations is classified correctly?
A) 19
B) 20
C) 7
D) 8
The following questions are based on the problem description and the output below.
A college admissions officer wants to evaluate graduate school applicants based on their GMAT scores, verbal and quantitative. Students are classified as either successful (Group 1), marginally successful (Group 2) or not-successful (Group 3) in their graduate studies. The officer has data on 20 current students, 7 successful (Group 1), 6 marginally successful (Group 2) and 7 not successful (Group 3).
Refer to Exhibit 10.2. What number of observations is classified correctly?
A) 19
B) 20
C) 7
D) 8
سؤال
Exhibit 10.2
The following questions are based on the problem description and the output below.
A college admissions officer wants to evaluate graduate school applicants based on their GMAT scores, verbal and quantitative. Students are classified as either successful (Group 1), marginally successful (Group 2) or not-successful (Group 3) in their graduate studies. The officer has data on 20 current students, 7 successful (Group 1), 6 marginally successful (Group 2) and 7 not successful (Group 3).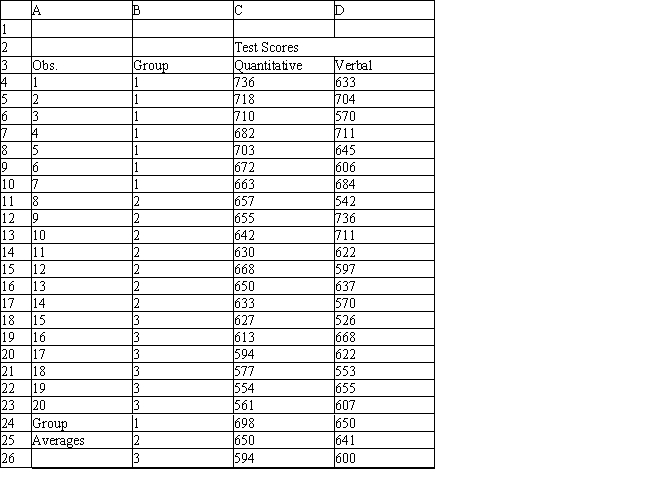


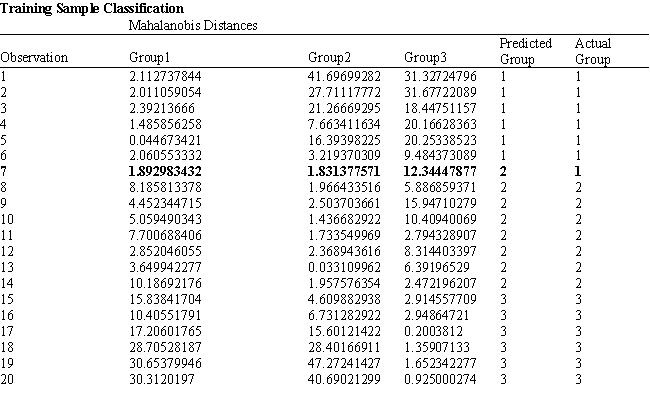

Refer to Exhibit 10.2. What is the verbal test score value of the group centroid for group 1?
A) 697.71
B) 647.86
C) 587.67
D) 650.43
The following questions are based on the problem description and the output below.
A college admissions officer wants to evaluate graduate school applicants based on their GMAT scores, verbal and quantitative. Students are classified as either successful (Group 1), marginally successful (Group 2) or not-successful (Group 3) in their graduate studies. The officer has data on 20 current students, 7 successful (Group 1), 6 marginally successful (Group 2) and 7 not successful (Group 3).
Refer to Exhibit 10.2. What is the verbal test score value of the group centroid for group 1?
A) 697.71
B) 647.86
C) 587.67
D) 650.43
سؤال
سؤال
سؤال
Exhibit 10.1
The following questions are based on the problem description and the output below.
A college admissions officer wants to evaluate graduate school applicants based on their GMAT scores, verbal and quantitative. Students are classified as either successful or not-successful in their graduate studies. The officer has data on 20 current students, ten of whom are doing very well (Group 1) and ten who are not (Group 2).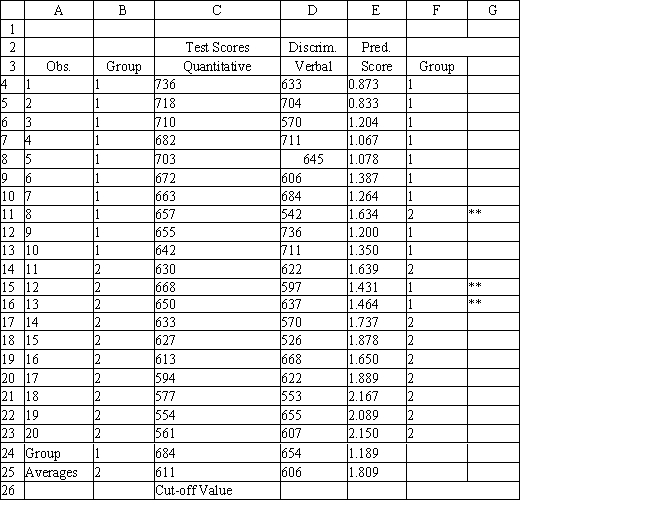
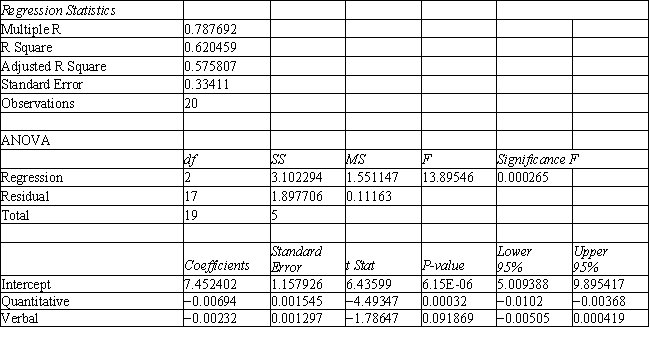

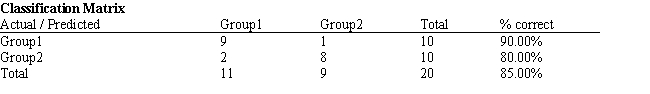
Refer to Exhibit 10.1. What percentage of the observations is classified incorrectly?
A) 90%
B) 80%
C) 85%
D) 15%
The following questions are based on the problem description and the output below.
A college admissions officer wants to evaluate graduate school applicants based on their GMAT scores, verbal and quantitative. Students are classified as either successful or not-successful in their graduate studies. The officer has data on 20 current students, ten of whom are doing very well (Group 1) and ten who are not (Group 2).
Refer to Exhibit 10.1. What percentage of the observations is classified incorrectly?
A) 90%
B) 80%
C) 85%
D) 15%
سؤال
سؤال
سؤال
سؤال
سؤال
سؤال
سؤال
سؤال
Exhibit 10.1
The following questions are based on the problem description and the output below.
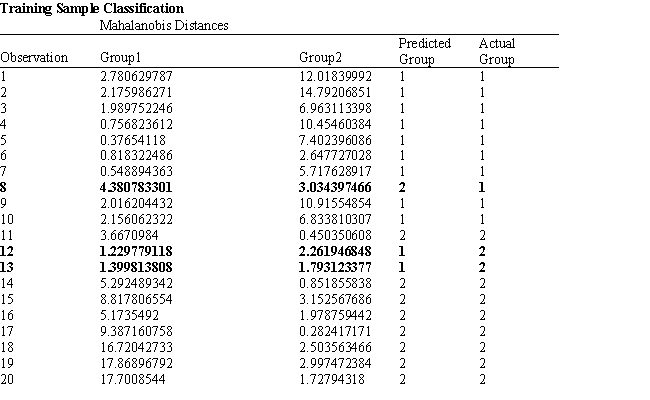
A college admissions officer wants to evaluate graduate school applicants based on their GMAT scores, verbal and quantitative. Students are classified as either successful or not-successful in their graduate studies. The officer has data on 20 current students, ten of whom are doing very well (Group 1) and ten who are not (Group 2).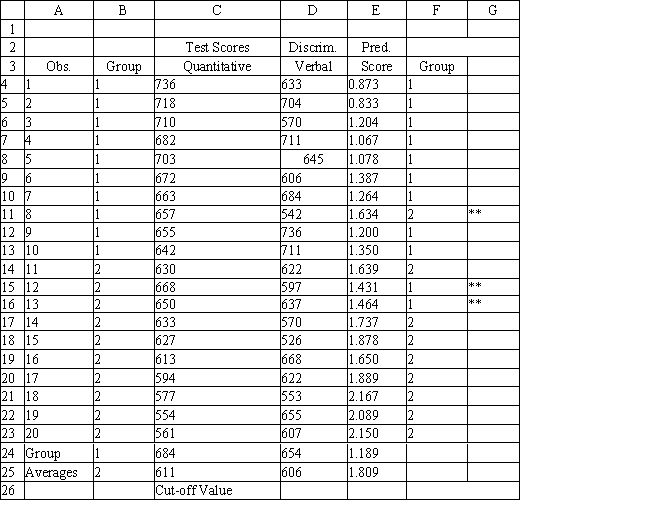

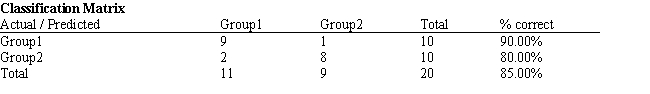
Refer to Exhibit 10.1. What is the quantitative test score value of the group centroid for group 2?
A) 683.8
B) 654.2
C) 610.7
D) 605.7
The following questions are based on the problem description and the output below.
A college admissions officer wants to evaluate graduate school applicants based on their GMAT scores, verbal and quantitative. Students are classified as either successful or not-successful in their graduate studies. The officer has data on 20 current students, ten of whom are doing very well (Group 1) and ten who are not (Group 2).
Refer to Exhibit 10.1. What is the quantitative test score value of the group centroid for group 2?
A) 683.8
B) 654.2
C) 610.7
D) 605.7
سؤال
Exhibit 10.1
The following questions are based on the problem description and the output below.
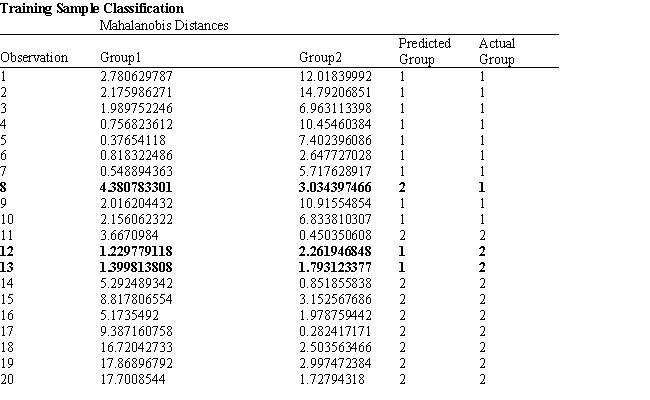
A college admissions officer wants to evaluate graduate school applicants based on their GMAT scores, verbal and quantitative. Students are classified as either successful or not-successful in their graduate studies. The officer has data on 20 current students, ten of whom are doing very well (Group 1) and ten who are not (Group 2).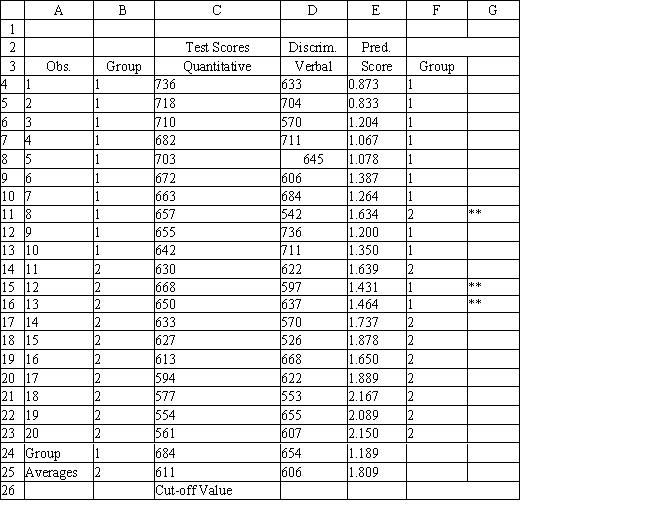

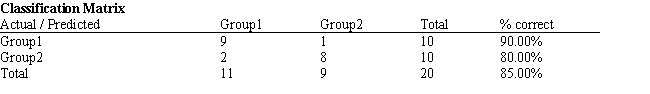
Refer to Exhibit 10.1. The university has received applications from several new students and would like to predict which group they would fall into. What is the discriminant score for a student with a Quantitative score of 686 and a Verbal score of 601. Use five (5) significant figures in your coefficients.
A) 1.29 ≤ discriminant score ≤ 1.30
B) 1.69 ≤ discriminant score ≤ 1.70
C) 2.69 ≤ discriminant score ≤ 2.70
D) 6.05 ≤ discriminant score ≤ 6.06
The following questions are based on the problem description and the output below.
A college admissions officer wants to evaluate graduate school applicants based on their GMAT scores, verbal and quantitative. Students are classified as either successful or not-successful in their graduate studies. The officer has data on 20 current students, ten of whom are doing very well (Group 1) and ten who are not (Group 2).
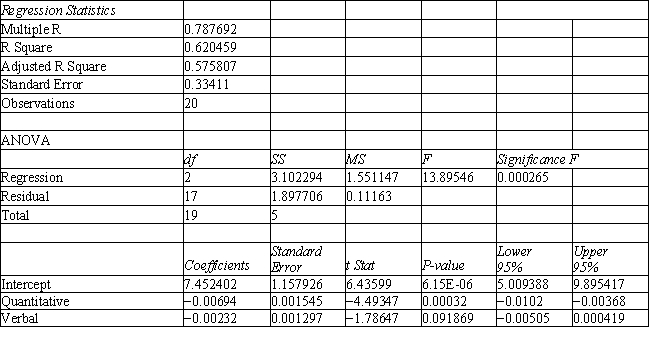
Refer to Exhibit 10.1. The university has received applications from several new students and would like to predict which group they would fall into. What is the discriminant score for a student with a Quantitative score of 686 and a Verbal score of 601. Use five (5) significant figures in your coefficients.
A) 1.29 ≤ discriminant score ≤ 1.30
B) 1.69 ≤ discriminant score ≤ 1.70
C) 2.69 ≤ discriminant score ≤ 2.70
D) 6.05 ≤ discriminant score ≤ 6.06
سؤال
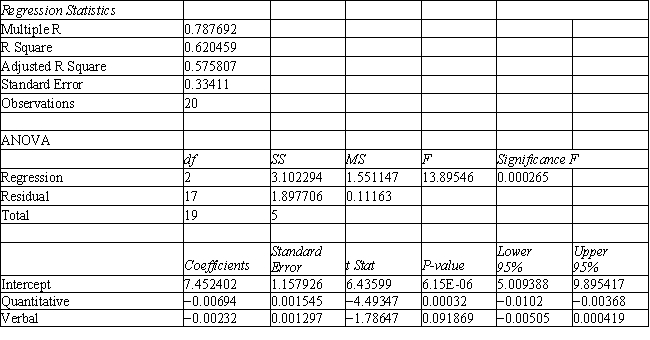
The dependent variable 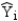 in the regression equation
in the regression equation 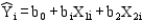 represents
represents
A) the estimated value of the dependent variable.
B) the estimated value of the Group variable.
C) the estimated ranking of the subject
D) all of these are true.
in the regression equation representsA) the estimated value of the dependent variable.
B) the estimated value of the Group variable.
C) the estimated ranking of the subject
D) all of these are true.
سؤال
سؤال
سؤال
سؤال
سؤال
سؤال
سؤال
سؤال
سؤال
سؤال
The discriminant score is denoted by
A)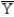
B)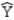
C) Yi
D)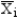
A)
B)
C) Yi
D)
سؤال
سؤال
سؤال
سؤال
سؤال
سؤال
Exhibit 10.2
The following questions are based on the problem description and the output below.
A college admissions officer wants to evaluate graduate school applicants based on their GMAT scores, verbal and quantitative. Students are classified as either successful (Group 1), marginally successful (Group 2) or not-successful (Group 3) in their graduate studies. The officer has data on 20 current students, 7 successful (Group 1), 6 marginally successful (Group 2) and 7 not successful (Group 3).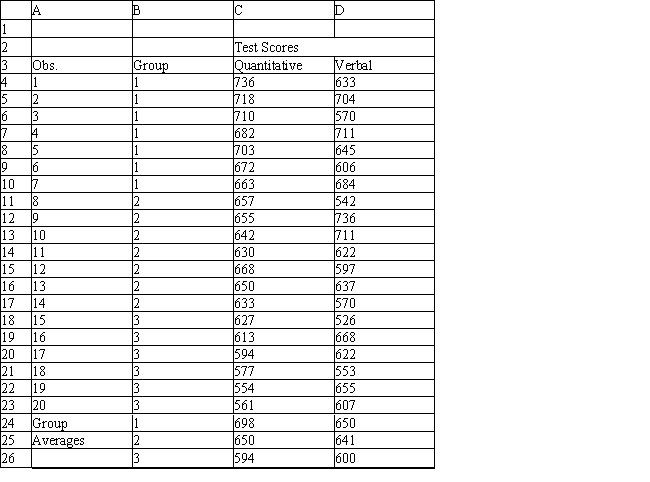


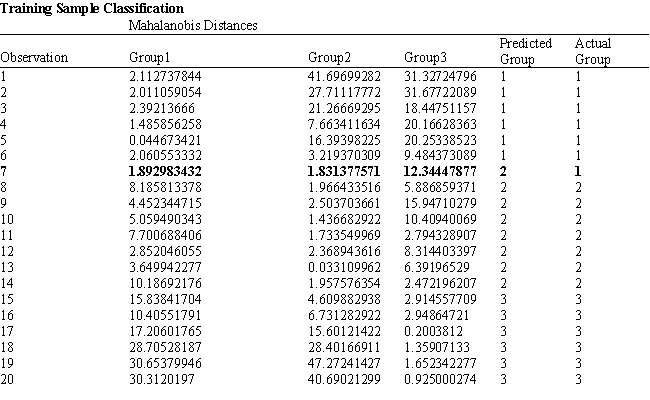

Refer to Exhibit 10.2. What percentage of observations is classified incorrectly?
A) 5%
B) 15%
C) 95%
D) 90%
The following questions are based on the problem description and the output below.
A college admissions officer wants to evaluate graduate school applicants based on their GMAT scores, verbal and quantitative. Students are classified as either successful (Group 1), marginally successful (Group 2) or not-successful (Group 3) in their graduate studies. The officer has data on 20 current students, 7 successful (Group 1), 6 marginally successful (Group 2) and 7 not successful (Group 3).
Refer to Exhibit 10.2. What percentage of observations is classified incorrectly?
A) 5%
B) 15%
C) 95%
D) 90%
سؤال
سؤال
سؤال
سؤال
سؤال
سؤال
سؤال
سؤال
Exhibit 10.1
The following questions are based on the problem description and the output below.
A college admissions officer wants to evaluate graduate school applicants based on their GMAT scores, verbal and quantitative. Students are classified as either successful or not-successful in their graduate studies. The officer has data on 20 current students, ten of whom are doing very well (Group 1) and ten who are not (Group 2).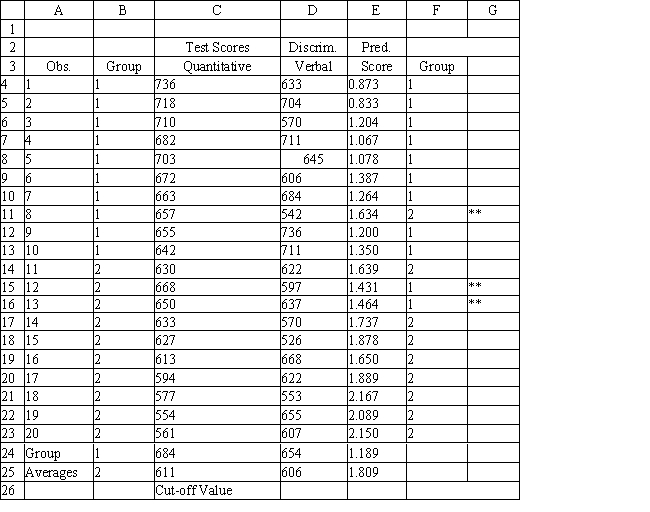
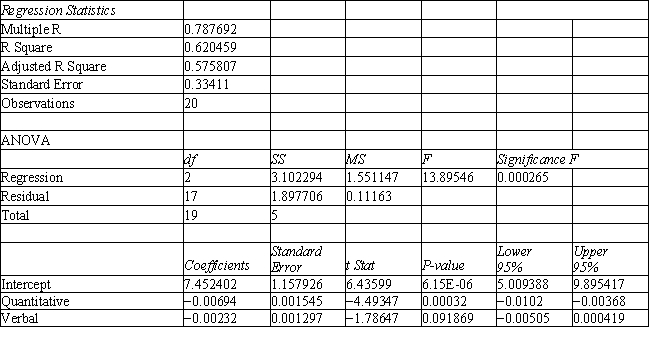

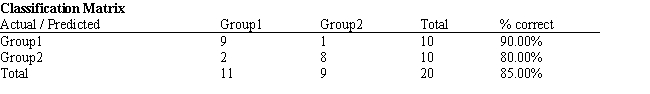
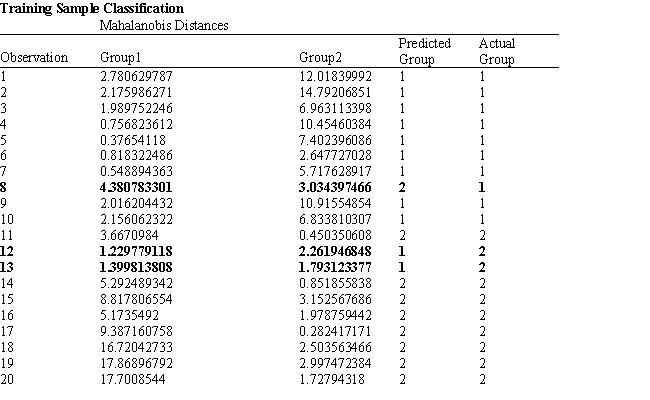
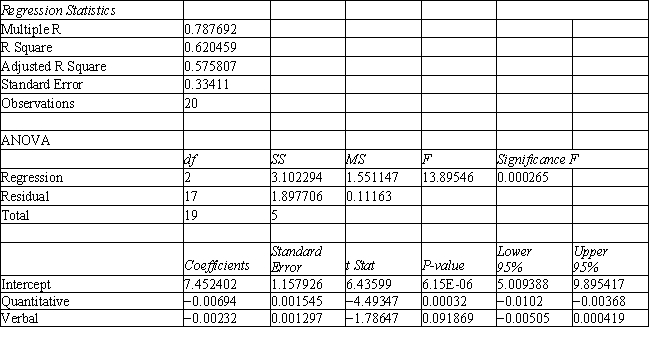
Refer to Exhibit 10.1. Based on the regression output, what is the discriminant score for a student with a quantitative score of 635 and a verbal score of 570?
A) 1.72 ≤ discriminant score ≤ 1.73
B) 2.02 ≤ discriminant score ≤ 2.03
C) 3.04 ≤ discriminant score ≤ 3.05
D) 6.12 ≤ discriminant score ≤ 6.14
The following questions are based on the problem description and the output below.
A college admissions officer wants to evaluate graduate school applicants based on their GMAT scores, verbal and quantitative. Students are classified as either successful or not-successful in their graduate studies. The officer has data on 20 current students, ten of whom are doing very well (Group 1) and ten who are not (Group 2).
Refer to Exhibit 10.1. Based on the regression output, what is the discriminant score for a student with a quantitative score of 635 and a verbal score of 570?
A) 1.72 ≤ discriminant score ≤ 1.73
B) 2.02 ≤ discriminant score ≤ 2.03
C) 3.04 ≤ discriminant score ≤ 3.05
D) 6.12 ≤ discriminant score ≤ 6.14
سؤال
سؤال
سؤال
سؤال
Given the following confusion matrix  what is the correct classification rate?
what is the correct classification rate?
A) 9/13 = 69%
B) 10/14 = 86%
C) 19/25 = 76%
D) 6/19 = 32%
what is the correct classification rate?A) 9/13 = 69%
B) 10/14 = 86%
C) 19/25 = 76%
D) 6/19 = 32%
سؤال
سؤال
سؤال
سؤال
سؤال
Exhibit 10.2
The following questions are based on the problem description and the output below.
A college admissions officer wants to evaluate graduate school applicants based on their GMAT scores, verbal and quantitative. Students are classified as either successful (Group 1), marginally successful (Group 2) or not-successful (Group 3) in their graduate studies. The officer has data on 20 current students, 7 successful (Group 1), 6 marginally successful (Group 2) and 7 not successful (Group 3).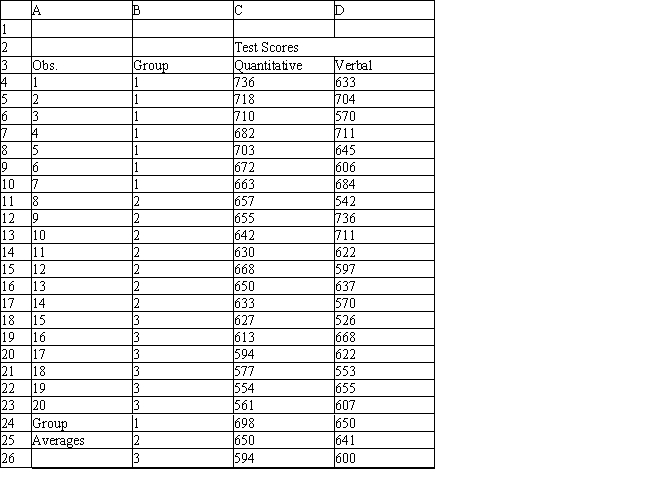


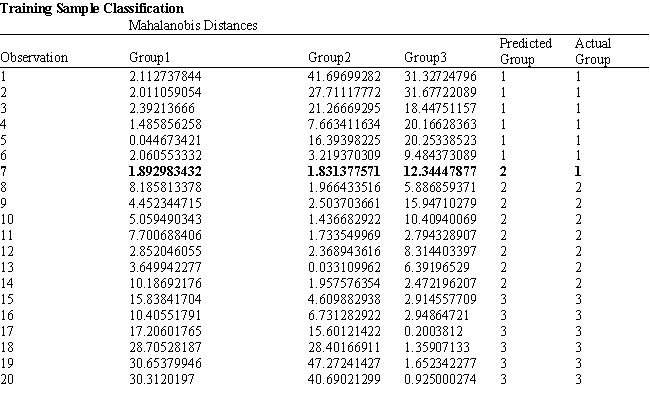

Refer to Exhibit 10.2. What number of observations is classified incorrectly?
A) 19
B) 20
C) 7
D) 1
The following questions are based on the problem description and the output below.
A college admissions officer wants to evaluate graduate school applicants based on their GMAT scores, verbal and quantitative. Students are classified as either successful (Group 1), marginally successful (Group 2) or not-successful (Group 3) in their graduate studies. The officer has data on 20 current students, 7 successful (Group 1), 6 marginally successful (Group 2) and 7 not successful (Group 3).
Refer to Exhibit 10.2. What number of observations is classified incorrectly?
A) 19
B) 20
C) 7
D) 1
سؤال
سؤال
Exhibit 10.1
The following questions are based on the problem description and the output below.
A college admissions officer wants to evaluate graduate school applicants based on their GMAT scores, verbal and quantitative. Students are classified as either successful or not-successful in their graduate studies. The officer has data on 20 current students, ten of whom are doing very well (Group 1) and ten who are not (Group 2).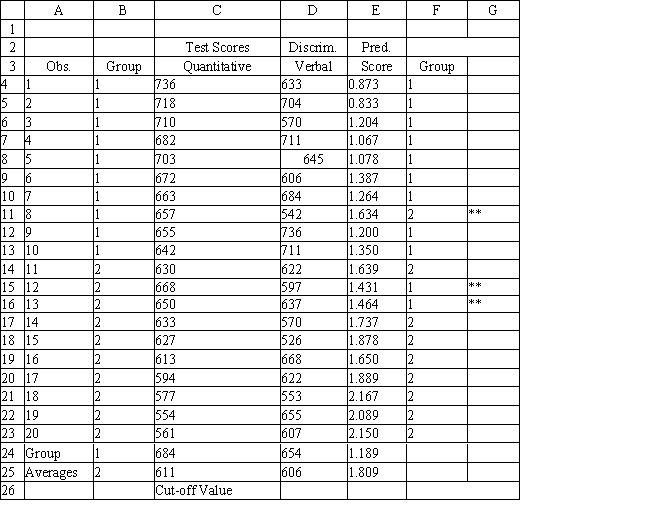
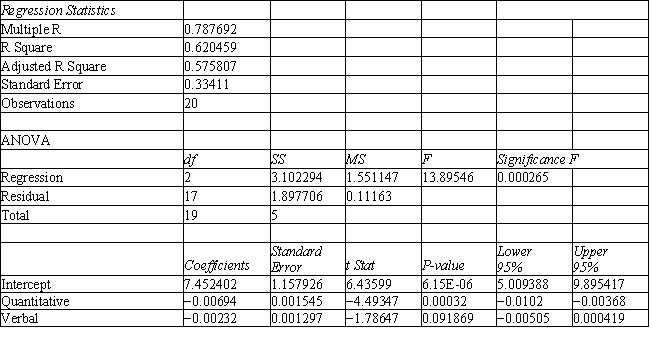

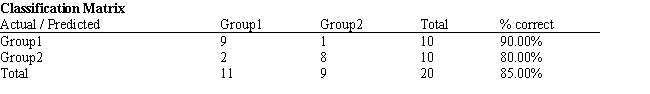
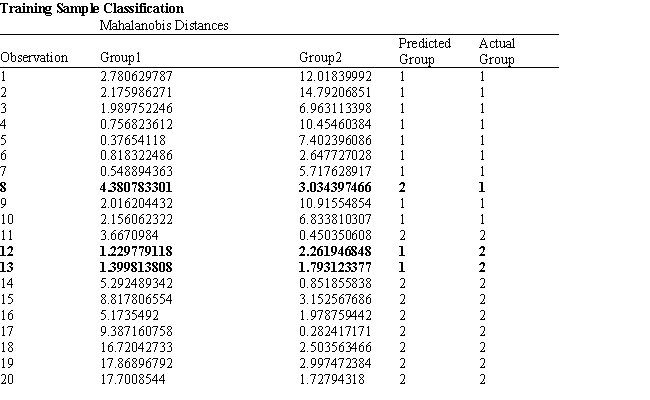
Refer to Exhibit 10.1. What is the verbal test score value of the group centroid for group 2?
A) 683.8
B) 654.2
C) 610.7
D) 605.7
The following questions are based on the problem description and the output below.
A college admissions officer wants to evaluate graduate school applicants based on their GMAT scores, verbal and quantitative. Students are classified as either successful or not-successful in their graduate studies. The officer has data on 20 current students, ten of whom are doing very well (Group 1) and ten who are not (Group 2).
Refer to Exhibit 10.1. What is the verbal test score value of the group centroid for group 2?
A) 683.8
B) 654.2
C) 610.7
D) 605.7
سؤال
Exhibit 10.1
The following questions are based on the problem description and the output below.
A college admissions officer wants to evaluate graduate school applicants based on their GMAT scores, verbal and quantitative. Students are classified as either successful or not-successful in their graduate studies. The officer has data on 20 current students, ten of whom are doing very well (Group 1) and ten who are not (Group 2).
Refer to Exhibit 10.1. What is the quantitative test score value of the group centroid for group 1?
A) 683.8
B) 654.2
C) 610.7
D) 605.7
The following questions are based on the problem description and the output below.
A college admissions officer wants to evaluate graduate school applicants based on their GMAT scores, verbal and quantitative. Students are classified as either successful or not-successful in their graduate studies. The officer has data on 20 current students, ten of whom are doing very well (Group 1) and ten who are not (Group 2).
Refer to Exhibit 10.1. What is the quantitative test score value of the group centroid for group 1?
A) 683.8
B) 654.2
C) 610.7
D) 605.7
سؤال
سؤال
سؤال
سؤال
سؤال
سؤال
سؤال
سؤال
سؤال
سؤال
سؤال
سؤال
سؤال
سؤال
Exhibit 10.1
The following questions are based on the problem description and the output below.
A college admissions officer wants to evaluate graduate school applicants based on their GMAT scores, verbal and quantitative. Students are classified as either successful or not-successful in their graduate studies. The officer has data on 20 current students, ten of whom are doing very well (Group 1) and ten who are not (Group 2).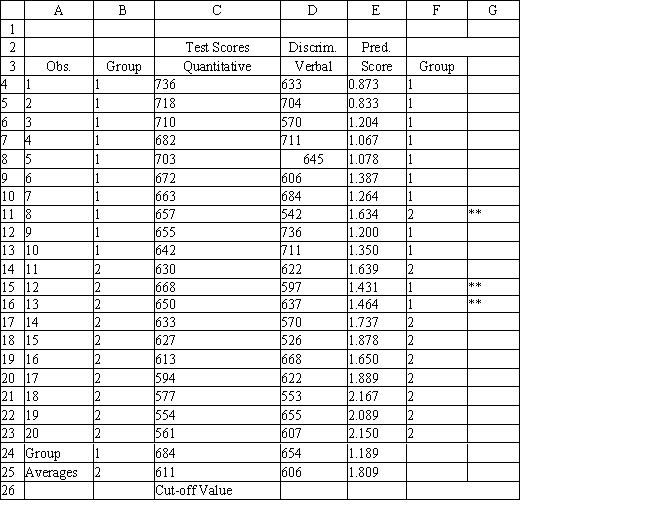

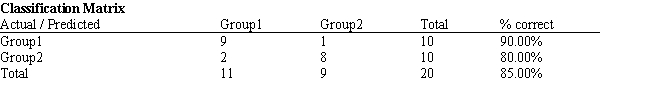

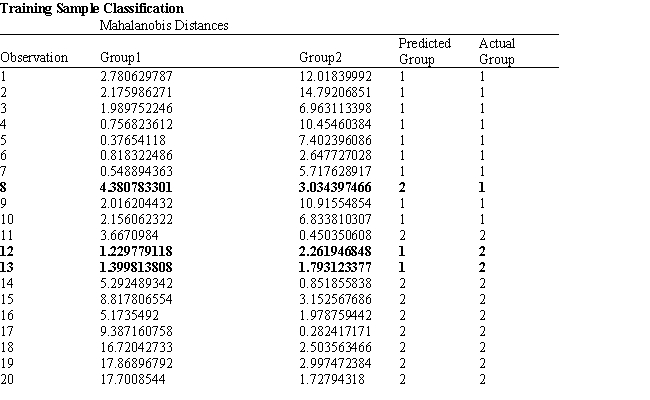
Refer to Exhibit 10.1. Suppose that for a given observation, the difference between Mahalanobis distances between group 1 and 2 (G1-G2) is big and negative. This means that
A) The observation is likely to be classified correctly to group 2
B) The observation is likely to be classified correctly to group 1
C) The observation is likely to be classified incorrectly to group 2
D) The observation is likely to be classified incorrectly to group 1
The following questions are based on the problem description and the output below.
A college admissions officer wants to evaluate graduate school applicants based on their GMAT scores, verbal and quantitative. Students are classified as either successful or not-successful in their graduate studies. The officer has data on 20 current students, ten of whom are doing very well (Group 1) and ten who are not (Group 2).
Refer to Exhibit 10.1. Suppose that for a given observation, the difference between Mahalanobis distances between group 1 and 2 (G1-G2) is big and negative. This means that
A) The observation is likely to be classified correctly to group 2
B) The observation is likely to be classified correctly to group 1
C) The observation is likely to be classified incorrectly to group 2
D) The observation is likely to be classified incorrectly to group 1
سؤال
سؤال
سؤال
سؤال

فتح الحزمة
قم بالتسجيل لفتح البطاقات في هذه المجموعة!
Unlock Deck
Unlock Deck
1/125
العب
ملء الشاشة (f)
Deck 10: Data Mining
1
The data might be normalized so that each variable is expressed on a common scale.
True
2
Classification refers to a type of data mining problem that uses the information available in a set of independent variables to predict the value of a discrete, or categorical, dependent variable.
True
3
Exhibit 10.2
The following questions are based on the problem description and the output below.
A college admissions officer wants to evaluate graduate school applicants based on their GMAT scores, verbal and quantitative. Students are classified as either successful (Group 1), marginally successful (Group 2) or not-successful (Group 3) in their graduate studies. The officer has data on 20 current students, 7 successful (Group 1), 6 marginally successful (Group 2) and 7 not successful (Group 3).
Refer to Exhibit 10.2. What is the verbal test score value of the group centroid for group 3?
A) 697.71
B) 647.86
C) 587.67
D) 605.17
The following questions are based on the problem description and the output below.
A college admissions officer wants to evaluate graduate school applicants based on their GMAT scores, verbal and quantitative. Students are classified as either successful (Group 1), marginally successful (Group 2) or not-successful (Group 3) in their graduate studies. The officer has data on 20 current students, 7 successful (Group 1), 6 marginally successful (Group 2) and 7 not successful (Group 3).
Refer to Exhibit 10.2. What is the verbal test score value of the group centroid for group 3?
A) 697.71
B) 647.86
C) 587.67
D) 605.17
605.17
4
Data mining tasks fall into three potential categories: Classification, Prediction and Association/Segmentation.
فتح الحزمة
افتح القفل للوصول البطاقات البالغ عددها 125 في هذه المجموعة.
فتح الحزمة
k this deck
5
A classification tree is a graphical representation of a set of rules for classifying observations into one group.
فتح الحزمة
افتح القفل للوصول البطاقات البالغ عددها 125 في هذه المجموعة.
فتح الحزمة
k this deck
6
Affinity analysis is a data mining technique that attempts to discover
A) what goes with what
B) the relationship between independent vatiables
C) multicollinearity
D) causality
A) what goes with what
B) the relationship between independent vatiables
C) multicollinearity
D) causality
فتح الحزمة
افتح القفل للوصول البطاقات البالغ عددها 125 في هذه المجموعة.
فتح الحزمة
k this deck
7
Suppose that an analyst classified a new record using the following sequential steps (i) find identical records in the training sample, (ii) determine a group, to which majority of these records belong, (iii) assign the new record to the group in step (ii). This technique is called
A) naive Bayes
B) Bayes
C) conditional probability estimation
D) posterior probability estimation
A) naive Bayes
B) Bayes
C) conditional probability estimation
D) posterior probability estimation
فتح الحزمة
افتح القفل للوصول البطاقات البالغ عددها 125 في هذه المجموعة.
فتح الحزمة
k this deck
8
Data mining is the process of finding and extracting useful information and insights from large data sets.
فتح الحزمة
افتح القفل للوصول البطاقات البالغ عددها 125 في هذه المجموعة.
فتح الحزمة
k this deck
9
The Fisher classification scores can be converted to
A) a linear function for each of the groups in the classification problem
B) probabilities of group membership
C) a uniform distribution
D) a half-space
A) a linear function for each of the groups in the classification problem
B) probabilities of group membership
C) a uniform distribution
D) a half-space
فتح الحزمة
افتح القفل للوصول البطاقات البالغ عددها 125 في هذه المجموعة.
فتح الحزمة
k this deck
10
Exhibit 10.2
The following questions are based on the problem description and the output below.
A college admissions officer wants to evaluate graduate school applicants based on their GMAT scores, verbal and quantitative. Students are classified as either successful (Group 1), marginally successful (Group 2) or not-successful (Group 3) in their graduate studies. The officer has data on 20 current students, 7 successful (Group 1), 6 marginally successful (Group 2) and 7 not successful (Group 3).
Refer to Exhibit 10.2. What is the quantitative test score value of the group centroid for group 1?
A) 697.71
B) 647.86
C) 587.67
D) 650.43
The following questions are based on the problem description and the output below.
A college admissions officer wants to evaluate graduate school applicants based on their GMAT scores, verbal and quantitative. Students are classified as either successful (Group 1), marginally successful (Group 2) or not-successful (Group 3) in their graduate studies. The officer has data on 20 current students, 7 successful (Group 1), 6 marginally successful (Group 2) and 7 not successful (Group 3).
Refer to Exhibit 10.2. What is the quantitative test score value of the group centroid for group 1?
A) 697.71
B) 647.86
C) 587.67
D) 650.43
فتح الحزمة
افتح القفل للوصول البطاقات البالغ عددها 125 في هذه المجموعة.
فتح الحزمة
k this deck
11
Exhibit 10.2
The following questions are based on the problem description and the output below.
A college admissions officer wants to evaluate graduate school applicants based on their GMAT scores, verbal and quantitative. Students are classified as either successful (Group 1), marginally successful (Group 2) or not-successful (Group 3) in their graduate studies. The officer has data on 20 current students, 7 successful (Group 1), 6 marginally successful (Group 2) and 7 not successful (Group 3).
Refer to Exhibit 10.2. What percentage of observations is classified correctly?
A) 100%
B) 85.71%
C) 95%
D) 90%
The following questions are based on the problem description and the output below.
A college admissions officer wants to evaluate graduate school applicants based on their GMAT scores, verbal and quantitative. Students are classified as either successful (Group 1), marginally successful (Group 2) or not-successful (Group 3) in their graduate studies. The officer has data on 20 current students, 7 successful (Group 1), 6 marginally successful (Group 2) and 7 not successful (Group 3).
Refer to Exhibit 10.2. What percentage of observations is classified correctly?
A) 100%
B) 85.71%
C) 95%
D) 90%
فتح الحزمة
افتح القفل للوصول البطاقات البالغ عددها 125 في هذه المجموعة.
فتح الحزمة
k this deck
12
Exhibit 10.2
The following questions are based on the problem description and the output below.
A college admissions officer wants to evaluate graduate school applicants based on their GMAT scores, verbal and quantitative. Students are classified as either successful (Group 1), marginally successful (Group 2) or not-successful (Group 3) in their graduate studies. The officer has data on 20 current students, 7 successful (Group 1), 6 marginally successful (Group 2) and 7 not successful (Group 3).
Refer to Exhibit 10.2. What number of observations is classified correctly?
A) 19
B) 20
C) 7
D) 8
The following questions are based on the problem description and the output below.
A college admissions officer wants to evaluate graduate school applicants based on their GMAT scores, verbal and quantitative. Students are classified as either successful (Group 1), marginally successful (Group 2) or not-successful (Group 3) in their graduate studies. The officer has data on 20 current students, 7 successful (Group 1), 6 marginally successful (Group 2) and 7 not successful (Group 3).
Refer to Exhibit 10.2. What number of observations is classified correctly?
A) 19
B) 20
C) 7
D) 8
فتح الحزمة
افتح القفل للوصول البطاقات البالغ عددها 125 في هذه المجموعة.
فتح الحزمة
k this deck
13
Exhibit 10.2
The following questions are based on the problem description and the output below.
A college admissions officer wants to evaluate graduate school applicants based on their GMAT scores, verbal and quantitative. Students are classified as either successful (Group 1), marginally successful (Group 2) or not-successful (Group 3) in their graduate studies. The officer has data on 20 current students, 7 successful (Group 1), 6 marginally successful (Group 2) and 7 not successful (Group 3).
Refer to Exhibit 10.2. What is the verbal test score value of the group centroid for group 1?
A) 697.71
B) 647.86
C) 587.67
D) 650.43
The following questions are based on the problem description and the output below.
A college admissions officer wants to evaluate graduate school applicants based on their GMAT scores, verbal and quantitative. Students are classified as either successful (Group 1), marginally successful (Group 2) or not-successful (Group 3) in their graduate studies. The officer has data on 20 current students, 7 successful (Group 1), 6 marginally successful (Group 2) and 7 not successful (Group 3).
Refer to Exhibit 10.2. What is the verbal test score value of the group centroid for group 1?
A) 697.71
B) 647.86
C) 587.67
D) 650.43
فتح الحزمة
افتح القفل للوصول البطاقات البالغ عددها 125 في هذه المجموعة.
فتح الحزمة
k this deck
14
The Mahalanobis distance measure accounts for differences in the covariances between all possible pairings of the independent variables.
فتح الحزمة
افتح القفل للوصول البطاقات البالغ عددها 125 في هذه المجموعة.
فتح الحزمة
k this deck
15
If using the regression tool for two-group discriminant analysis, in the regression dialog box, the Input X-Range entry corresponds to
A) the Group values.
B) the independent variable values.
C) the predicted variable values.
D) the fitted variable values.
A) the Group values.
B) the independent variable values.
C) the predicted variable values.
D) the fitted variable values.
فتح الحزمة
افتح القفل للوصول البطاقات البالغ عددها 125 في هذه المجموعة.
فتح الحزمة
k this deck
16
Exhibit 10.1
The following questions are based on the problem description and the output below.
A college admissions officer wants to evaluate graduate school applicants based on their GMAT scores, verbal and quantitative. Students are classified as either successful or not-successful in their graduate studies. The officer has data on 20 current students, ten of whom are doing very well (Group 1) and ten who are not (Group 2).
Refer to Exhibit 10.1. What percentage of the observations is classified incorrectly?
A) 90%
B) 80%
C) 85%
D) 15%
The following questions are based on the problem description and the output below.
A college admissions officer wants to evaluate graduate school applicants based on their GMAT scores, verbal and quantitative. Students are classified as either successful or not-successful in their graduate studies. The officer has data on 20 current students, ten of whom are doing very well (Group 1) and ten who are not (Group 2).
Refer to Exhibit 10.1. What percentage of the observations is classified incorrectly?
A) 90%
B) 80%
C) 85%
D) 15%
فتح الحزمة
افتح القفل للوصول البطاقات البالغ عددها 125 في هذه المجموعة.
فتح الحزمة
k this deck
17
In hierarchical clustering, the measure of similarity between clusters is/are
A) single linkage
B) complete linkage
C) Ward's method
D) all of the above
A) single linkage
B) complete linkage
C) Ward's method
D) all of the above
فتح الحزمة
افتح القفل للوصول البطاقات البالغ عددها 125 في هذه المجموعة.
فتح الحزمة
k this deck
18
The Get Data command is part of the XLMiner Platform in Excel add-on.
فتح الحزمة
افتح القفل للوصول البطاقات البالغ عددها 125 في هذه المجموعة.
فتح الحزمة
k this deck
19
The k-nearest neighbor (k-NN) technique identifies the k observations in the training data that are most similar (or nearest) to a new observation we want to classify.
فتح الحزمة
افتح القفل للوصول البطاقات البالغ عددها 125 في هذه المجموعة.
فتح الحزمة
k this deck
20
When purity is perfect, the Gini index is equal to
A) 0
B) 0.25
C) 0.5
D) 1
A) 0
B) 0.25
C) 0.5
D) 1
فتح الحزمة
افتح القفل للوصول البطاقات البالغ عددها 125 في هذه المجموعة.
فتح الحزمة
k this deck
21
In discriminant analysis the averages for the independent variables for a group define the
A) centroid.
B) median.
C) mode.
D) central tendency.
A) centroid.
B) median.
C) mode.
D) central tendency.
فتح الحزمة
افتح القفل للوصول البطاقات البالغ عددها 125 في هذه المجموعة.
فتح الحزمة
k this deck
22
One element in cleaning the data set in the mining process involves
A) removing unimportant variables
B) adding more variables to the data set
C) calculating the adjusted R2
D) calculating the coefficient of multiple correlation
A) removing unimportant variables
B) adding more variables to the data set
C) calculating the adjusted R2
D) calculating the coefficient of multiple correlation
فتح الحزمة
افتح القفل للوصول البطاقات البالغ عددها 125 في هذه المجموعة.
فتح الحزمة
k this deck
23
Discriminant analysis (DA) differs from most other predictive statistical methods because the dependent variable is
A) continuous
B) random
C) stochastic
D) discrete
A) continuous
B) random
C) stochastic
D) discrete
فتح الحزمة
افتح القفل للوصول البطاقات البالغ عددها 125 في هذه المجموعة.
فتح الحزمة
k this deck
24
Exhibit 10.1
The following questions are based on the problem description and the output below.
A college admissions officer wants to evaluate graduate school applicants based on their GMAT scores, verbal and quantitative. Students are classified as either successful or not-successful in their graduate studies. The officer has data on 20 current students, ten of whom are doing very well (Group 1) and ten who are not (Group 2).
Refer to Exhibit 10.1. What is the quantitative test score value of the group centroid for group 2?
A) 683.8
B) 654.2
C) 610.7
D) 605.7
The following questions are based on the problem description and the output below.
A college admissions officer wants to evaluate graduate school applicants based on their GMAT scores, verbal and quantitative. Students are classified as either successful or not-successful in their graduate studies. The officer has data on 20 current students, ten of whom are doing very well (Group 1) and ten who are not (Group 2).
Refer to Exhibit 10.1. What is the quantitative test score value of the group centroid for group 2?
A) 683.8
B) 654.2
C) 610.7
D) 605.7
فتح الحزمة
افتح القفل للوصول البطاقات البالغ عددها 125 في هذه المجموعة.
فتح الحزمة
k this deck
25
Exhibit 10.1
The following questions are based on the problem description and the output below.
A college admissions officer wants to evaluate graduate school applicants based on their GMAT scores, verbal and quantitative. Students are classified as either successful or not-successful in their graduate studies. The officer has data on 20 current students, ten of whom are doing very well (Group 1) and ten who are not (Group 2).
Refer to Exhibit 10.1. The university has received applications from several new students and would like to predict which group they would fall into. What is the discriminant score for a student with a Quantitative score of 686 and a Verbal score of 601. Use five (5) significant figures in your coefficients.
A) 1.29 ≤ discriminant score ≤ 1.30
B) 1.69 ≤ discriminant score ≤ 1.70
C) 2.69 ≤ discriminant score ≤ 2.70
D) 6.05 ≤ discriminant score ≤ 6.06
The following questions are based on the problem description and the output below.
A college admissions officer wants to evaluate graduate school applicants based on their GMAT scores, verbal and quantitative. Students are classified as either successful or not-successful in their graduate studies. The officer has data on 20 current students, ten of whom are doing very well (Group 1) and ten who are not (Group 2).
Refer to Exhibit 10.1. The university has received applications from several new students and would like to predict which group they would fall into. What is the discriminant score for a student with a Quantitative score of 686 and a Verbal score of 601. Use five (5) significant figures in your coefficients.
A) 1.29 ≤ discriminant score ≤ 1.30
B) 1.69 ≤ discriminant score ≤ 1.70
C) 2.69 ≤ discriminant score ≤ 2.70
D) 6.05 ≤ discriminant score ≤ 6.06
فتح الحزمة
افتح القفل للوصول البطاقات البالغ عددها 125 في هذه المجموعة.
فتح الحزمة
k this deck
26
The dependent variable in the regression equation represents
A) the estimated value of the dependent variable.
B) the estimated value of the Group variable.
C) the estimated ranking of the subject
D) all of these are true.
in the regression equation representsA) the estimated value of the dependent variable.
B) the estimated value of the Group variable.
C) the estimated ranking of the subject
D) all of these are true.
فتح الحزمة
افتح القفل للوصول البطاقات البالغ عددها 125 في هذه المجموعة.
فتح الحزمة
k this deck
27
Useful data mining techniques can be found in Excel under ___________ drop menu
A) Data/(Data Analysis)
B) Regression
C) Histogram
D) Insert/Chart
A) Data/(Data Analysis)
B) Regression
C) Histogram
D) Insert/Chart
فتح الحزمة
افتح القفل للوصول البطاقات البالغ عددها 125 في هذه المجموعة.
فتح الحزمة
k this deck
28
In hierarchical clustering, the measure of similarity between clusters is/are
A) single linkage
B) average linkage
C) average group linkage
D) all of the above
A) single linkage
B) average linkage
C) average group linkage
D) all of the above
فتح الحزمة
افتح القفل للوصول البطاقات البالغ عددها 125 في هذه المجموعة.
فتح الحزمة
k this deck
29
The k-means clustering algorithm is available
A) in XLMiner Excel add-in
B) as a regression option in Excel
C) as ANOVA option in Excel
D) as one of the options under non-parametric statistics in Excel
A) in XLMiner Excel add-in
B) as a regression option in Excel
C) as ANOVA option in Excel
D) as one of the options under non-parametric statistics in Excel
فتح الحزمة
افتح القفل للوصول البطاقات البالغ عددها 125 في هذه المجموعة.
فتح الحزمة
k this deck
30
Overfitting refers to
A) placing too much emphasis on the sample-specific noise
B) fitting the model too tightly
C) fitting the model too loosely
D) underestimating model parameters
A) placing too much emphasis on the sample-specific noise
B) fitting the model too tightly
C) fitting the model too loosely
D) underestimating model parameters
فتح الحزمة
افتح القفل للوصول البطاقات البالغ عددها 125 في هذه المجموعة.
فتح الحزمة
k this deck
31
Prediction step in data mining is an option available in
A) XLMiner Excel add-in
B) Excel
C) data mining software
D) nonlinear multivariate regression
A) XLMiner Excel add-in
B) Excel
C) data mining software
D) nonlinear multivariate regression
فتح الحزمة
افتح القفل للوصول البطاقات البالغ عددها 125 في هذه المجموعة.
فتح الحزمة
k this deck
32
Suppose that two variables are found to be significantly correlated. A researcher may
A) remove one variable from the data set
B) replace the two variables by their product
C) replace the two variables by their squared difference
D) remove both variables from the data set
A) remove one variable from the data set
B) replace the two variables by their product
C) replace the two variables by their squared difference
D) remove both variables from the data set
فتح الحزمة
افتح القفل للوصول البطاقات البالغ عددها 125 في هذه المجموعة.
فتح الحزمة
k this deck
33
Steps in the data mining process include the following (in sequence)
A) (identify opportunity), (collect data), (explore, understand and prepare data), (identify tasks and tools, (partition data), (build and evaluate models), (deploy models)
B) (identify opportunity), (collect data), (explore, understand and prepare data), (identify tasks and tools, (build and evaluate models), (deploy models)
C) (collect data), (explore, understand and prepare data), (identify tasks and tools, (partition data), (build and evaluate models), (deploy models)
D) (identify opportunity), (collect data), (identify tasks and tools, (partition data), (build and evaluate models), (deploy models)
A) (identify opportunity), (collect data), (explore, understand and prepare data), (identify tasks and tools, (partition data), (build and evaluate models), (deploy models)
B) (identify opportunity), (collect data), (explore, understand and prepare data), (identify tasks and tools, (build and evaluate models), (deploy models)
C) (collect data), (explore, understand and prepare data), (identify tasks and tools, (partition data), (build and evaluate models), (deploy models)
D) (identify opportunity), (collect data), (identify tasks and tools, (partition data), (build and evaluate models), (deploy models)
فتح الحزمة
افتح القفل للوصول البطاقات البالغ عددها 125 في هذه المجموعة.
فتح الحزمة
k this deck
34
Suppose that the correlation coefficient between X1 and X2 is equal to -1. This means that
A) X1 and X2 are perfectly positively correlated
B) X1 and X2 are perfectly negatively correlated
C) X1 and X2 are weakly and positively correlated
D) X1 and X2 are weakly and negatively correlated
A) X1 and X2 are perfectly positively correlated
B) X1 and X2 are perfectly negatively correlated
C) X1 and X2 are weakly and positively correlated
D) X1 and X2 are weakly and negatively correlated
فتح الحزمة
افتح القفل للوصول البطاقات البالغ عددها 125 في هذه المجموعة.
فتح الحزمة
k this deck
35
____________ is a classification technique that estimates the probability of an observation belonging to a particular group
A) logistic regression
B) binary regression
C) multivariate analysis
D) ANCOVA
A) logistic regression
B) binary regression
C) multivariate analysis
D) ANCOVA
فتح الحزمة
افتح القفل للوصول البطاقات البالغ عددها 125 في هذه المجموعة.
فتح الحزمة
k this deck
36
The discriminant score is denoted by
A)
B)
C) Yi
D)
A)
B)
C) Yi
D)
فتح الحزمة
افتح القفل للوصول البطاقات البالغ عددها 125 في هذه المجموعة.
فتح الحزمة
k this deck
37
The Fisher linear discriminant function
A) identifies a linear function for each of the groups in the classification problem
B) fits a nonlinear function for each of the groups in the classification problem
C) defines a hyperplane
D) defines a half-space
A) identifies a linear function for each of the groups in the classification problem
B) fits a nonlinear function for each of the groups in the classification problem
C) defines a hyperplane
D) defines a half-space
فتح الحزمة
افتح القفل للوصول البطاقات البالغ عددها 125 في هذه المجموعة.
فتح الحزمة
k this deck
38
In a two-group discriminant analysis problem using regression, why is the midpoint cut-off value used to determine group classification?
A) Because the value minimizes the absolute misclassification error.
B) Because the value minimizes the probability of misclassification error.
C) Because the value represents an equal division between the groups.
D) Because the value incorporates problem specific knowledge.
A) Because the value minimizes the absolute misclassification error.
B) Because the value minimizes the probability of misclassification error.
C) Because the value represents an equal division between the groups.
D) Because the value incorporates problem specific knowledge.
فتح الحزمة
افتح القفل للوصول البطاقات البالغ عددها 125 في هذه المجموعة.
فتح الحزمة
k this deck
39
In the k nearest neighbor technique, a small value of k produces classifications that are
A) very sensitive to the sample-specific characteristics of the training data
B) not sensitive to the sample-specific characteristics of the training data
C) robust
D) reliable
A) very sensitive to the sample-specific characteristics of the training data
B) not sensitive to the sample-specific characteristics of the training data
C) robust
D) reliable
فتح الحزمة
افتح القفل للوصول البطاقات البالغ عددها 125 في هذه المجموعة.
فتح الحزمة
k this deck
40
Suppose that there are 3 variables in a data set. Approximately how many data records are required using a rule of thumb discussed in the textbook?
A) 30 to 45
B) 20 to 30
C) 45 to 60
D) 50 to 100
A) 30 to 45
B) 20 to 30
C) 45 to 60
D) 50 to 100
فتح الحزمة
افتح القفل للوصول البطاقات البالغ عددها 125 في هذه المجموعة.
فتح الحزمة
k this deck
41
The parameters of the logistic regression model
A) are derived through a nonlinear maximum likelihood estimation procedure
B) are negative
C) are positive
D) are negative fractions
A) are derived through a nonlinear maximum likelihood estimation procedure
B) are negative
C) are positive
D) are negative fractions
فتح الحزمة
افتح القفل للوصول البطاقات البالغ عددها 125 في هذه المجموعة.
فتح الحزمة
k this deck
42
Exhibit 10.2
The following questions are based on the problem description and the output below.
A college admissions officer wants to evaluate graduate school applicants based on their GMAT scores, verbal and quantitative. Students are classified as either successful (Group 1), marginally successful (Group 2) or not-successful (Group 3) in their graduate studies. The officer has data on 20 current students, 7 successful (Group 1), 6 marginally successful (Group 2) and 7 not successful (Group 3).
Refer to Exhibit 10.2. What percentage of observations is classified incorrectly?
A) 5%
B) 15%
C) 95%
D) 90%
The following questions are based on the problem description and the output below.
A college admissions officer wants to evaluate graduate school applicants based on their GMAT scores, verbal and quantitative. Students are classified as either successful (Group 1), marginally successful (Group 2) or not-successful (Group 3) in their graduate studies. The officer has data on 20 current students, 7 successful (Group 1), 6 marginally successful (Group 2) and 7 not successful (Group 3).
Refer to Exhibit 10.2. What percentage of observations is classified incorrectly?
A) 5%
B) 15%
C) 95%
D) 90%
فتح الحزمة
افتح القفل للوصول البطاقات البالغ عددها 125 في هذه المجموعة.
فتح الحزمة
k this deck
43
Suppose that a data set contains a variable EDUCATION, which has 7 discrete levels. EDUCATION is an example of
A) a categorical variable
B) a classification variable
C) a continuous variable
D) an exponential variable
A) a categorical variable
B) a classification variable
C) a continuous variable
D) an exponential variable
فتح الحزمة
افتح القفل للوصول البطاقات البالغ عددها 125 في هذه المجموعة.
فتح الحزمة
k this deck
44
Logistic regression in XLMiner add-in can be used for ______ groups
A) 2
B) 3
C) 4
D) 5
A) 2
B) 3
C) 4
D) 5
فتح الحزمة
افتح القفل للوصول البطاقات البالغ عددها 125 في هذه المجموعة.
فتح الحزمة
k this deck
45
Data mining tasks fall in the following categories
A) classification, prediction, association
B) categorization, segmentation
C) prediction, association, mining
D) observation, categorization, association
A) classification, prediction, association
B) categorization, segmentation
C) prediction, association, mining
D) observation, categorization, association
فتح الحزمة
افتح القفل للوصول البطاقات البالغ عددها 125 في هذه المجموعة.
فتح الحزمة
k this deck
46
Cluster analysis is a data mining technique used for
A) grouping together similar data
B) segmentation of records within a data set
C) designing effective marketing strategies
D) all of the above
A) grouping together similar data
B) segmentation of records within a data set
C) designing effective marketing strategies
D) all of the above
فتح الحزمة
افتح القفل للوصول البطاقات البالغ عددها 125 في هذه المجموعة.
فتح الحزمة
k this deck
47
Neural networks classification methodology
A) is one of the options available in XLMiner Excel add-in
B) is superior to other classification schemes
C) is inferior to other classification schemes
D) produces results that are identical to the outcomes of the DA technique
A) is one of the options available in XLMiner Excel add-in
B) is superior to other classification schemes
C) is inferior to other classification schemes
D) produces results that are identical to the outcomes of the DA technique
فتح الحزمة
افتح القفل للوصول البطاقات البالغ عددها 125 في هذه المجموعة.
فتح الحزمة
k this deck
48
Technique(s) used in classification step of data mining include
A) discriminant analysis
B) logistic regression
C) neural networks
D) all of the above
A) discriminant analysis
B) logistic regression
C) neural networks
D) all of the above
فتح الحزمة
افتح القفل للوصول البطاقات البالغ عددها 125 في هذه المجموعة.
فتح الحزمة
k this deck
49
In the ________ step of data mining, a researcher attempts to form logical groupings of data in the set
A) classification
B) prediction
C) categorization
D) association/segmentation
A) classification
B) prediction
C) categorization
D) association/segmentation
فتح الحزمة
افتح القفل للوصول البطاقات البالغ عددها 125 في هذه المجموعة.
فتح الحزمة
k this deck
50
Exhibit 10.1
The following questions are based on the problem description and the output below.
A college admissions officer wants to evaluate graduate school applicants based on their GMAT scores, verbal and quantitative. Students are classified as either successful or not-successful in their graduate studies. The officer has data on 20 current students, ten of whom are doing very well (Group 1) and ten who are not (Group 2).
Refer to Exhibit 10.1. Based on the regression output, what is the discriminant score for a student with a quantitative score of 635 and a verbal score of 570?
A) 1.72 ≤ discriminant score ≤ 1.73
B) 2.02 ≤ discriminant score ≤ 2.03
C) 3.04 ≤ discriminant score ≤ 3.05
D) 6.12 ≤ discriminant score ≤ 6.14
The following questions are based on the problem description and the output below.
A college admissions officer wants to evaluate graduate school applicants based on their GMAT scores, verbal and quantitative. Students are classified as either successful or not-successful in their graduate studies. The officer has data on 20 current students, ten of whom are doing very well (Group 1) and ten who are not (Group 2).
Refer to Exhibit 10.1. Based on the regression output, what is the discriminant score for a student with a quantitative score of 635 and a verbal score of 570?
A) 1.72 ≤ discriminant score ≤ 1.73
B) 2.02 ≤ discriminant score ≤ 2.03
C) 3.04 ≤ discriminant score ≤ 3.05
D) 6.12 ≤ discriminant score ≤ 6.14
فتح الحزمة
افتح القفل للوصول البطاقات البالغ عددها 125 في هذه المجموعة.
فتح الحزمة
k this deck
51
Logistic regression is a classification technique that
A) outperforms other techniques accros a variety of data collections
B) is not reliable
C) is not robust
D) is not feasible for most data sets
A) outperforms other techniques accros a variety of data collections
B) is not reliable
C) is not robust
D) is not feasible for most data sets
فتح الحزمة
افتح القفل للوصول البطاقات البالغ عددها 125 في هذه المجموعة.
فتح الحزمة
k this deck
52
___________ and _________ must be chosen each time a partition is subdivided
A) an independent variable and splitting value
B) a dependent variable and cutoff value
C) a significance level and an upper bound
D) a significance level and a lower bound
A) an independent variable and splitting value
B) a dependent variable and cutoff value
C) a significance level and an upper bound
D) a significance level and a lower bound
فتح الحزمة
افتح القفل للوصول البطاقات البالغ عددها 125 في هذه المجموعة.
فتح الحزمة
k this deck
53
A graphical representation of a set of rules for classifying observations into 2 or more groups is called
A) a classification tree
B) a binary tree
C) a Pareto diagram
D) a branch-and-bound tree
A) a classification tree
B) a binary tree
C) a Pareto diagram
D) a branch-and-bound tree
فتح الحزمة
افتح القفل للوصول البطاقات البالغ عددها 125 في هذه المجموعة.
فتح الحزمة
k this deck
54
Given the following confusion matrix what is the correct classification rate?
A) 9/13 = 69%
B) 10/14 = 86%
C) 19/25 = 76%
D) 6/19 = 32%
what is the correct classification rate?A) 9/13 = 69%
B) 10/14 = 86%
C) 19/25 = 76%
D) 6/19 = 32%
فتح الحزمة
افتح القفل للوصول البطاقات البالغ عددها 125 في هذه المجموعة.
فتح الحزمة
k this deck
55
Plots useful in data mining analysis can be accessed in Excel using the _______ add-in
A) XLMiner
B) Charts
C) Data Analysis
D) Visual Basic
A) XLMiner
B) Charts
C) Data Analysis
D) Visual Basic
فتح الحزمة
افتح القفل للوصول البطاقات البالغ عددها 125 في هذه المجموعة.
فتح الحزمة
k this deck
56
Neural networks are
A) a pattern recognition technique
B) a physical model representation of interrelationships
C) a non-directed graph
D) a binary network
A) a pattern recognition technique
B) a physical model representation of interrelationships
C) a non-directed graph
D) a binary network
فتح الحزمة
افتح القفل للوصول البطاقات البالغ عددها 125 في هذه المجموعة.
فتح الحزمة
k this deck
57
Suppose that all observations belong to the same class. The entropy measure for this situation is equal to
A) 0
B) 0.25
C) 0.5
D) 1
A) 0
B) 0.25
C) 0.5
D) 1
فتح الحزمة
افتح القفل للوصول البطاقات البالغ عددها 125 في هذه المجموعة.
فتح الحزمة
k this deck
58
Two approaches to clustering discussed in the text are
A) k-means clustering and hierarchical clustering
B) intuitive clustering and methodical clustering
C) MIPS clustering and pixel clustering
D) centroid clustering and VMI
A) k-means clustering and hierarchical clustering
B) intuitive clustering and methodical clustering
C) MIPS clustering and pixel clustering
D) centroid clustering and VMI
فتح الحزمة
افتح القفل للوصول البطاقات البالغ عددها 125 في هذه المجموعة.
فتح الحزمة
k this deck
59
Exhibit 10.2
The following questions are based on the problem description and the output below.
A college admissions officer wants to evaluate graduate school applicants based on their GMAT scores, verbal and quantitative. Students are classified as either successful (Group 1), marginally successful (Group 2) or not-successful (Group 3) in their graduate studies. The officer has data on 20 current students, 7 successful (Group 1), 6 marginally successful (Group 2) and 7 not successful (Group 3).
Refer to Exhibit 10.2. What number of observations is classified incorrectly?
A) 19
B) 20
C) 7
D) 1
The following questions are based on the problem description and the output below.
A college admissions officer wants to evaluate graduate school applicants based on their GMAT scores, verbal and quantitative. Students are classified as either successful (Group 1), marginally successful (Group 2) or not-successful (Group 3) in their graduate studies. The officer has data on 20 current students, 7 successful (Group 1), 6 marginally successful (Group 2) and 7 not successful (Group 3).
Refer to Exhibit 10.2. What number of observations is classified incorrectly?
A) 19
B) 20
C) 7
D) 1
فتح الحزمة
افتح القفل للوصول البطاقات البالغ عددها 125 في هذه المجموعة.
فتح الحزمة
k this deck
60
Suppose that a data set contains a variable EDUCATION, which has 7 discrete levels. EDUCATION can be represented by ____ binary variables
A) 6
B) 7
C) 8
D) 9
A) 6
B) 7
C) 8
D) 9
فتح الحزمة
افتح القفل للوصول البطاقات البالغ عددها 125 في هذه المجموعة.
فتح الحزمة
k this deck
61
Exhibit 10.1
The following questions are based on the problem description and the output below.
A college admissions officer wants to evaluate graduate school applicants based on their GMAT scores, verbal and quantitative. Students are classified as either successful or not-successful in their graduate studies. The officer has data on 20 current students, ten of whom are doing very well (Group 1) and ten who are not (Group 2).
Refer to Exhibit 10.1. What is the verbal test score value of the group centroid for group 2?
A) 683.8
B) 654.2
C) 610.7
D) 605.7
The following questions are based on the problem description and the output below.
A college admissions officer wants to evaluate graduate school applicants based on their GMAT scores, verbal and quantitative. Students are classified as either successful or not-successful in their graduate studies. The officer has data on 20 current students, ten of whom are doing very well (Group 1) and ten who are not (Group 2).
Refer to Exhibit 10.1. What is the verbal test score value of the group centroid for group 2?
A) 683.8
B) 654.2
C) 610.7
D) 605.7
فتح الحزمة
افتح القفل للوصول البطاقات البالغ عددها 125 في هذه المجموعة.
فتح الحزمة
k this deck
62
Exhibit 10.1
The following questions are based on the problem description and the output below.
A college admissions officer wants to evaluate graduate school applicants based on their GMAT scores, verbal and quantitative. Students are classified as either successful or not-successful in their graduate studies. The officer has data on 20 current students, ten of whom are doing very well (Group 1) and ten who are not (Group 2).
Refer to Exhibit 10.1. What is the quantitative test score value of the group centroid for group 1?
A) 683.8
B) 654.2
C) 610.7
D) 605.7
The following questions are based on the problem description and the output below.
A college admissions officer wants to evaluate graduate school applicants based on their GMAT scores, verbal and quantitative. Students are classified as either successful or not-successful in their graduate studies. The officer has data on 20 current students, ten of whom are doing very well (Group 1) and ten who are not (Group 2).
Refer to Exhibit 10.1. What is the quantitative test score value of the group centroid for group 1?
A) 683.8
B) 654.2
C) 610.7
D) 605.7
فتح الحزمة
افتح القفل للوصول البطاقات البالغ عددها 125 في هذه المجموعة.
فتح الحزمة
k this deck
63
Suppose that the correlation coefficient between X1 and X2 is equal to 1. This means that
A) X1 and X2 are perfectly positively correlated
B) X1 and X2 are perfectly negatively correlated
C) X1 and X2 are weakly and positively correlated
D) X1 and X2 are weakly and negatively correlated
A) X1 and X2 are perfectly positively correlated
B) X1 and X2 are perfectly negatively correlated
C) X1 and X2 are weakly and positively correlated
D) X1 and X2 are weakly and negatively correlated
فتح الحزمة
افتح القفل للوصول البطاقات البالغ عددها 125 في هذه المجموعة.
فتح الحزمة
k this deck
64
A graphical representation of clustering outcomes showing which items should be classified to which clusters is called a(n)
A) dendrogram
B) hierarchical chart
C) horizontal multi layer chart
D) vertical bar chart
A) dendrogram
B) hierarchical chart
C) horizontal multi layer chart
D) vertical bar chart
فتح الحزمة
افتح القفل للوصول البطاقات البالغ عددها 125 في هذه المجموعة.
فتح الحزمة
k this deck
65
A major challenge in affinity analysis is to
A) identify the most meaningful rules used to determine what goes with what
B) the conditional probabilities
C) the posterior probabilities
D) the probabilities of states of nature
A) identify the most meaningful rules used to determine what goes with what
B) the conditional probabilities
C) the posterior probabilities
D) the probabilities of states of nature
فتح الحزمة
افتح القفل للوصول البطاقات البالغ عددها 125 في هذه المجموعة.
فتح الحزمة
k this deck
66
The objective of classification tree algorithms is to
A) minimize the average weighted impurity of the resulting partitions
B) maximize the average weighted impurity of the resulting partitions
C) maximize the average weighted purity of the resulting partitions
D) maximize the likelihood estimator of the resulting partitions
A) minimize the average weighted impurity of the resulting partitions
B) maximize the average weighted impurity of the resulting partitions
C) maximize the average weighted purity of the resulting partitions
D) maximize the likelihood estimator of the resulting partitions
فتح الحزمة
افتح القفل للوصول البطاقات البالغ عددها 125 في هذه المجموعة.
فتح الحزمة
k this deck
67
The first step in creating a classification tree involves
A) recursively partitioning the independent variables using the outcome of previous partitions
B) creating a subset of variables
C) clustering the variables into a larger superset
D) deciding the number of partitions
A) recursively partitioning the independent variables using the outcome of previous partitions
B) creating a subset of variables
C) clustering the variables into a larger superset
D) deciding the number of partitions
فتح الحزمة
افتح القفل للوصول البطاقات البالغ عددها 125 في هذه المجموعة.
فتح الحزمة
k this deck
68
In the ________ step of data mining, a researcher attempts to predict the value of a continuous response variable based on the data set
A) classification
B) prediction
C) categorization
D) association/segmentation
A) classification
B) prediction
C) categorization
D) association/segmentation
فتح الحزمة
افتح القفل للوصول البطاقات البالغ عددها 125 في هذه المجموعة.
فتح الحزمة
k this deck
69
If using the regression tool for two-group discriminant analysis, in the regression dialog box, the Input Y-Range entry corresponds to
A) the Group values.
B) the independent variable values.
C) the predictor variable values.
D) (b) and (c) are both correct
A) the Group values.
B) the independent variable values.
C) the predictor variable values.
D) (b) and (c) are both correct
فتح الحزمة
افتح القفل للوصول البطاقات البالغ عددها 125 في هذه المجموعة.
فتح الحزمة
k this deck
70
In the k nearest neighbor technique, a large value of k produces classifications that
A) are very sensitive to the sample-specific characteristics of the training data
B) place all observations into the most frequently occurring group in the training data
C) are robust
D) are reliable
A) are very sensitive to the sample-specific characteristics of the training data
B) place all observations into the most frequently occurring group in the training data
C) are robust
D) are reliable
فتح الحزمة
افتح القفل للوصول البطاقات البالغ عددها 125 في هذه المجموعة.
فتح الحزمة
k this deck
71
A ______________ provides a visual summary of the improvements that a data mining project provides on a binary classification problem compared to a random guess
A) lift chart
B) Pareto chart
C) Gantt chart
D) histogram
A) lift chart
B) Pareto chart
C) Gantt chart
D) histogram
فتح الحزمة
افتح القفل للوصول البطاقات البالغ عددها 125 في هذه المجموعة.
فتح الحزمة
k this deck
72
Which of the following is not true regarding discriminant analysis?
A) The classification rule translates discriminant scores into group membership.
B) Discriminant analysis is based on discrete or categorical dependent variables.
C) The classification rule selected perfectly classifies the data used to derive the classification rule.
D) The confusion matrix summarizes classification results.
A) The classification rule translates discriminant scores into group membership.
B) Discriminant analysis is based on discrete or categorical dependent variables.
C) The classification rule selected perfectly classifies the data used to derive the classification rule.
D) The confusion matrix summarizes classification results.
فتح الحزمة
افتح القفل للوصول البطاقات البالغ عددها 125 في هذه المجموعة.
فتح الحزمة
k this deck
73
The k-nearest neighbor classification technique
A) identifies the k observations in the training data that are most similar to a new observation we want to classify
B) sorts the data in an increasing order
C) sorts the data in a decreasing order
D) works very much like the ranking algorithm
A) identifies the k observations in the training data that are most similar to a new observation we want to classify
B) sorts the data in an increasing order
C) sorts the data in a decreasing order
D) works very much like the ranking algorithm
فتح الحزمة
افتح القفل للوصول البطاقات البالغ عددها 125 في هذه المجموعة.
فتح الحزمة
k this deck
74
A ___________ algorithm is used during the training process to adjust weights in a neural network
A) backpropagation
B) branch-and-bound
C) Simplex
D) cutting plane
A) backpropagation
B) branch-and-bound
C) Simplex
D) cutting plane
فتح الحزمة
افتح القفل للوصول البطاقات البالغ عددها 125 في هذه المجموعة.
فتح الحزمة
k this deck
75
Affinity analysis is a data mining technique used in marketing research to determine
A) which products are purchased together
B) product clusters
C) the likelihood that a product will be purchased
D) causality
A) which products are purchased together
B) product clusters
C) the likelihood that a product will be purchased
D) causality
فتح الحزمة
افتح القفل للوصول البطاقات البالغ عددها 125 في هذه المجموعة.
فتح الحزمة
k this deck
76
Exhibit 10.1
The following questions are based on the problem description and the output below.
A college admissions officer wants to evaluate graduate school applicants based on their GMAT scores, verbal and quantitative. Students are classified as either successful or not-successful in their graduate studies. The officer has data on 20 current students, ten of whom are doing very well (Group 1) and ten who are not (Group 2).
Refer to Exhibit 10.1. Suppose that for a given observation, the difference between Mahalanobis distances between group 1 and 2 (G1-G2) is big and negative. This means that
A) The observation is likely to be classified correctly to group 2
B) The observation is likely to be classified correctly to group 1
C) The observation is likely to be classified incorrectly to group 2
D) The observation is likely to be classified incorrectly to group 1
The following questions are based on the problem description and the output below.
A college admissions officer wants to evaluate graduate school applicants based on their GMAT scores, verbal and quantitative. Students are classified as either successful or not-successful in their graduate studies. The officer has data on 20 current students, ten of whom are doing very well (Group 1) and ten who are not (Group 2).
Refer to Exhibit 10.1. Suppose that for a given observation, the difference between Mahalanobis distances between group 1 and 2 (G1-G2) is big and negative. This means that
A) The observation is likely to be classified correctly to group 2
B) The observation is likely to be classified correctly to group 1
C) The observation is likely to be classified incorrectly to group 2
D) The observation is likely to be classified incorrectly to group 1
فتح الحزمة
افتح القفل للوصول البطاقات البالغ عددها 125 في هذه المجموعة.
فتح الحزمة
k this deck
77
To create the training and validation data set for the model use the __________ option in the XLMiner tab
A) partition with oversampling
B) partition without oversampling
C) partition
D) sample
A) partition with oversampling
B) partition without oversampling
C) partition
D) sample
فتح الحزمة
افتح القفل للوصول البطاقات البالغ عددها 125 في هذه المجموعة.
فتح الحزمة
k this deck
78
A way to detecting and avoiding overfitting is to
A) use the validation sample to calibrate the model
B) use repeated runs of the model and averaging the results
C) use computer simulation
D) use rigorous statistical tools
A) use the validation sample to calibrate the model
B) use repeated runs of the model and averaging the results
C) use computer simulation
D) use rigorous statistical tools
فتح الحزمة
افتح القفل للوصول البطاقات البالغ عددها 125 في هذه المجموعة.
فتح الحزمة
k this deck
79
Suppose that all observations in partition j belong to the same group. The Gini index for this situation is equal to
A) 0
B) 0.25
C) 0.5
D) 1
A) 0
B) 0.25
C) 0.5
D) 1
فتح الحزمة
افتح القفل للوصول البطاقات البالغ عددها 125 في هذه المجموعة.
فتح الحزمة
k this deck
80
In using neural networks, an analyst must decide __________ and ___________
A) how many hidden layers to use and how many nodes to use in each of the hidden layers
B) how accurate the prediction should be and how many iterations to use
C) how many nodes to use and how much time to allow for simulation
D) how many iterations to use and what is the limit on the budget constraint
A) how many hidden layers to use and how many nodes to use in each of the hidden layers
B) how accurate the prediction should be and how many iterations to use
C) how many nodes to use and how much time to allow for simulation
D) how many iterations to use and what is the limit on the budget constraint
فتح الحزمة
افتح القفل للوصول البطاقات البالغ عددها 125 في هذه المجموعة.
فتح الحزمة
k this deck
فتح الحزمة
افتح القفل للوصول البطاقات البالغ عددها 125 في هذه المجموعة.








