Deck 17: Big Data: Hadoop, Spark, Nosql and Iot
Full screen (f)
Question
Question
Question
Question
Question
Question
Question
Question
Question
Which of the following statements is false?
A) A xe "relational database"xe "relational database"relational database is a logical table-based representation of data that allows the data to be accessed without consideration of its physical structure.
B) The following diagram shows a sample Employee table that might be used in a personnel system:

C) Part (b)'s Employee table's primary purpose is to store employees' attributes.
D) Tables are composed of columns, each describing a single entity. In Part (b)'s Employee table, each column represents one employee. Columns are composed of rows containing individual attribute values.
A) A xe "relational database"xe "relational database"relational database is a logical table-based representation of data that allows the data to be accessed without consideration of its physical structure.
B) The following diagram shows a sample Employee table that might be used in a personnel system:
C) Part (b)'s Employee table's primary purpose is to store employees' attributes.
D) Tables are composed of columns, each describing a single entity. In Part (b)'s Employee table, each column represents one employee. Columns are composed of rows containing individual attribute values.
Question
Question
Question
Question
Question
Question
Question
Question
Question
Question
Question
Question
Question
Question
Question
Question
Question
Question
Question
Question
Question
Question
Question
Question
Question
Question
Question
Question
Question
Question
Question
Question
Question
Question
Question
Question
Question
Question
Question
Question
Question
Question
Question
Question
Question
Question
Question
Question
Question
Question
Question
Question
Question
Question
Question
The following dashboard visualizes simulated sensors from the PubNub simulated IoT sensors stream: 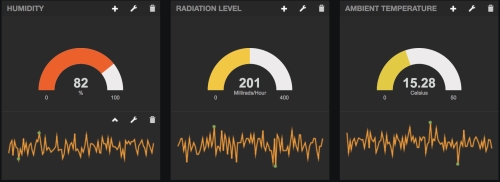 For each sensor, the visualization shows a Gauge (the semicircular visualizations) and a ________ (the jagged lines) to visualize the data.
For each sensor, the visualization shows a Gauge (the semicircular visualizations) and a ________ (the jagged lines) to visualize the data.
A) Sparkleline
B) Glowline
C) Sparkline
D) None of the above
For each sensor, the visualization shows a Gauge (the semicircular visualizations) and a ________ (the jagged lines) to visualize the data.A) Sparkleline
B) Glowline
C) Sparkline
D) None of the above
Question
Question
Question
Question
Question
Question
Question
Question
Question
Question
Question
Question
Question
Question
Question

Unlock Deck
Sign up to unlock the cards in this deck!
Unlock Deck
Unlock Deck
1/79
Play
Full screen (f)
Deck 17: Big Data: Hadoop, Spark, Nosql and Iot
1
Which of the following statements a), b) or c) is false?
A) Different database users are often interested in different data and different relationships among the data.
B) Most users require only subsets of a database table's rows and columns.
C) You use xe "Structured Query Language (SQL)"Structured Query Language (xe "SQL (Structured Query Language)"xe "SQL (Structured Query Language)"SQL) to define xe "query"queries. Queries specify which subsets of the data to select from a table.
D) All of the above statements are true.
A) Different database users are often interested in different data and different relationships among the data.
B) Most users require only subsets of a database table's rows and columns.
C) You use xe "Structured Query Language (SQL)"Structured Query Language (xe "SQL (Structured Query Language)"xe "SQL (Structured Query Language)"SQL) to define xe "query"queries. Queries specify which subsets of the data to select from a table.
D) All of the above statements are true.
D
2
Which of the following statements a), b) or c) is false?
A) A xe "primary key"primary key is a column (or group of columns) with a value that's unique for each row. This guarantees that each row can be identified by its primary key.
B) Examples of primary keys are social security numbers, employee ID numbers and part numbers in an inventory system-values in each of these are guaranteed to be unique.
C) The rows of a relational database table are always listed in ascending order by primary key.
D) All of the above statements are true.
A) A xe "primary key"primary key is a column (or group of columns) with a value that's unique for each row. This guarantees that each row can be identified by its primary key.
B) Examples of primary keys are social security numbers, employee ID numbers and part numbers in an inventory system-values in each of these are guaranteed to be unique.
C) The rows of a relational database table are always listed in ascending order by primary key.
D) All of the above statements are true.
C
3
Which of the following statements is false?
A) An Uxe "UPDATE SQL statement"PDATE statement modifies existing values in a table.
B) The UPDATE keyword is followed by the table to update, the keyword Sxe "SET SQL clause"ET and a comma-separated list of column_name : value pairs indicating the columns to change and their new values.
C) An UPDATE's change will be applied to every row if you do not specify a xe "WHERE SQL clause"WHERE clause. To make a change to only one row, it's best to use the row's unique primary key in the WHERE clause.
D) For statements that modify the database, the Cursor object's rowcount attribute contains an integer value representing the number of rows that were modified. If this value is 0, no changes were made.
A) An Uxe "UPDATE SQL statement"PDATE statement modifies existing values in a table.
B) The UPDATE keyword is followed by the table to update, the keyword Sxe "SET SQL clause"ET and a comma-separated list of column_name : value pairs indicating the columns to change and their new values.
C) An UPDATE's change will be applied to every row if you do not specify a xe "WHERE SQL clause"WHERE clause. To make a change to only one row, it's best to use the row's unique primary key in the WHERE clause.
D) For statements that modify the database, the Cursor object's rowcount attribute contains an integer value representing the number of rows that were modified. If this value is 0, no changes were made.
B
4
Which of the following statements is false?
A) You'll often select only a subset of the rows in a database that satisfy certain xe "selection criteria"selection criteria.
B) Only xe "row in a database table"rows that satisfy the selection criteria mentioned in Part (a)-formally called xe "predicate"predicates-are selected.
C) SQL's Wxe "WHERE SQL clause"HERE clause specifies a query's selection criteria.
D) The following code selects from a titles table the title, edition and copyright for all books with the copyright year 2016:
Pd)read_sql("""SELECT title, edition, copyright
FROM titles
WHERE copyright > '2016'""", connection)
A) You'll often select only a subset of the rows in a database that satisfy certain xe "selection criteria"selection criteria.
B) Only xe "row in a database table"rows that satisfy the selection criteria mentioned in Part (a)-formally called xe "predicate"predicates-are selected.
C) SQL's Wxe "WHERE SQL clause"HERE clause specifies a query's selection criteria.
D) The following code selects from a titles table the title, edition and copyright for all books with the copyright year 2016:
Pd)read_sql("""SELECT title, edition, copyright
FROM titles
WHERE copyright > '2016'""", connection)
Unlock Deck
Unlock for access to all 79 flashcards in this deck.
Unlock Deck
k this deck
5
Xe "author_ISBN table of books database"In SQL, a foreign key is a column in one table that matches a ________ column in another table.
A) domestic key
B) candidate key
C) primary key
D) None of the above
A) domestic key
B) candidate key
C) primary key
D) None of the above
Unlock Deck
Unlock for access to all 79 flashcards in this deck.
Unlock Deck
k this deck
6
xe "underscore:_ SQL wildcard character"________ in a pattern string indicates a single wildcard character at that position.
A) at sign (@)
B) uxe "_ SQL wildcard character"nderscore (_)
C) hash sign (#)
D) None of the above.
A) at sign (@)
B) uxe "_ SQL wildcard character"nderscore (_)
C) hash sign (#)
D) None of the above.
Unlock Deck
Unlock for access to all 79 flashcards in this deck.
Unlock Deck
k this deck
7
Xe "author_ISBN table of books database"In a relational database, every foreign-key value must appear as the primary-key value in a row of another table so the DBMS can ensure that the foreign-key value is valid. This is known as the ________.
A) Rule of Entity Integrity
B) xe "Rule of Referential Integrity"Rule of Referential Integrity
C) Rule of Guaranteed Access
D) None of the above
A) Rule of Entity Integrity
B) xe "Rule of Referential Integrity"Rule of Referential Integrity
C) Rule of Guaranteed Access
D) None of the above
Unlock Deck
Unlock for access to all 79 flashcards in this deck.
Unlock Deck
k this deck
8
Which of the following statements a), b) or c) is false?
A) As data continues growing exponentially, we want to learn from that data and do so at blazing speed.
B) Learning from big data requires sophisticated algorithms, hardware, software and networking designs.
C) With more data, and especially with big data, machine learning can be even more effective.
D) All of the above statements are true.
A) As data continues growing exponentially, we want to learn from that data and do so at blazing speed.
B) Learning from big data requires sophisticated algorithms, hardware, software and networking designs.
C) With more data, and especially with big data, machine learning can be even more effective.
D) All of the above statements are true.
Unlock Deck
Unlock for access to all 79 flashcards in this deck.
Unlock Deck
k this deck
9
Which of the following statements is false?
A) A xe "relational database"xe "relational database"relational database is a logical table-based representation of data that allows the data to be accessed without consideration of its physical structure.
B) The following diagram shows a sample Employee table that might be used in a personnel system:
C) Part (b)'s Employee table's primary purpose is to store employees' attributes.
D) Tables are composed of columns, each describing a single entity. In Part (b)'s Employee table, each column represents one employee. Columns are composed of rows containing individual attribute values.
A) A xe "relational database"xe "relational database"relational database is a logical table-based representation of data that allows the data to be accessed without consideration of its physical structure.
B) The following diagram shows a sample Employee table that might be used in a personnel system:
C) Part (b)'s Employee table's primary purpose is to store employees' attributes.
D) Tables are composed of columns, each describing a single entity. In Part (b)'s Employee table, each column represents one employee. Columns are composed of rows containing individual attribute values.
Unlock Deck
Unlock for access to all 79 flashcards in this deck.
Unlock Deck
k this deck
10
Which of the following statements a), b) or c) is false?
A) As big-data processing needs grow, the information-technology community is continually looking for ways to increase performance.
B) Spark was developed to perform certain big-data tasks more efficiently by breaking them into pieces that do lots of disk I/O across many computers.
C) Spark streaming processes streaming data in mini-batches. Spark streaming gathers data for a short time interval you specify, then gives you that batch of data to process.
D) You can use xe "Spark (Apache):Spark SQL"Spark SQL to query data stored in a Spark DataFrame which, unlike pandas DataFrames, may contain data distributed over many computers in a cluster.
A) As big-data processing needs grow, the information-technology community is continually looking for ways to increase performance.
B) Spark was developed to perform certain big-data tasks more efficiently by breaking them into pieces that do lots of disk I/O across many computers.
C) Spark streaming processes streaming data in mini-batches. Spark streaming gathers data for a short time interval you specify, then gives you that batch of data to process.
D) You can use xe "Spark (Apache):Spark SQL"Spark SQL to query data stored in a Spark DataFrame which, unlike pandas DataFrames, may contain data distributed over many computers in a cluster.
Unlock Deck
Unlock for access to all 79 flashcards in this deck.
Unlock Deck
k this deck
11
Which of the following statements a), b) or c) is false?
A) In the context of big data, NoSQL means what its name implies.
B) NoSQL databases are meant for xe "unstructured data"unstructured data, like photos, videos and the natural language found in e-mails, text messages and social-media posts, and xe "semi-structured data"semi-structured data like JSON and XML documents.
C) Semi-structured data often wraps unstructured data with additional information called metadata.
D) All of the above statements are true.
A) In the context of big data, NoSQL means what its name implies.
B) NoSQL databases are meant for xe "unstructured data"unstructured data, like photos, videos and the natural language found in e-mails, text messages and social-media posts, and xe "semi-structured data"semi-structured data like JSON and XML documents.
C) Semi-structured data often wraps unstructured data with additional information called metadata.
D) All of the above statements are true.
Unlock Deck
Unlock for access to all 79 flashcards in this deck.
Unlock Deck
k this deck
12
Which of the following statements is false?
A) For decades, relational database management systems (RDBMs) have been the standard in data processing.
B) RDBMs require xe "structured data"unstructured data that fits into neat rectangular tables.
C) As the size of the data and the number of tables and relationships increases, relational databases become more difficult to manipulate efficiently.
D) xe "NoSQL database"NoSQL and xe "NewSQL database"NewSQL databases have emerged to deal with the kinds of big data storage and processing demands that traditional relational databases cannot meet.
A) For decades, relational database management systems (RDBMs) have been the standard in data processing.
B) RDBMs require xe "structured data"unstructured data that fits into neat rectangular tables.
C) As the size of the data and the number of tables and relationships increases, relational databases become more difficult to manipulate efficiently.
D) xe "NoSQL database"NoSQL and xe "NewSQL database"NewSQL databases have emerged to deal with the kinds of big data storage and processing demands that traditional relational databases cannot meet.
Unlock Deck
Unlock for access to all 79 flashcards in this deck.
Unlock Deck
k this deck
13
Which of the following statements a), b) or c) is false?
A) The open-source xe "SQLite database management system"SQLite database management system is included with Python.
B) Only the SQLite database management system has Python support.
C) Each database management system that has Python support typically provides a module that adheres to Python's Database Application Programming Interface (DB-API), which specifies common object and method names for manipulating any database.
D) All of the above statements are true.
A) The open-source xe "SQLite database management system"SQLite database management system is included with Python.
B) Only the SQLite database management system has Python support.
C) Each database management system that has Python support typically provides a module that adheres to Python's Database Application Programming Interface (DB-API), which specifies common object and method names for manipulating any database.
D) All of the above statements are true.
Unlock Deck
Unlock for access to all 79 flashcards in this deck.
Unlock Deck
k this deck
14
Which of the following statements a), b) or c) is false?
A) You can merge data from multiple tables, referred to as xe "joining database tables"joining the tables, with Ixe "INNER JOIN SQL clause"NNER JOIN.
B) The INNER JOIN's Oxe "ON clause"N clause uses a primary-key column in one table and a foreign-key column in the other table to determine which rows to merge from each table.
C) xe "qualified name"Qualified name syntax (tableName.columnName) is required if the columns have the same name in both tables.
D) All of the above statements are true.
A) You can merge data from multiple tables, referred to as xe "joining database tables"joining the tables, with Ixe "INNER JOIN SQL clause"NNER JOIN.
B) The INNER JOIN's Oxe "ON clause"N clause uses a primary-key column in one table and a foreign-key column in the other table to determine which rows to merge from each table.
C) xe "qualified name"Qualified name syntax (tableName.columnName) is required if the columns have the same name in both tables.
D) All of the above statements are true.
Unlock Deck
Unlock for access to all 79 flashcards in this deck.
Unlock Deck
k this deck
15
Which of the following statements is false?
A) SQL can be used only to retrieve data from a relational database.
B) The pandas method read_sql uses a Cursor behind the scenes to execute queries and access the rows of the results.
C) The INSERT INTO statement inserts a xe "row in a database table"row into a table.
D) The SQL keywords INSERT INTO are followed by the table in which to insert the new row and a comma-separated list of column names in parentheses.
A) SQL can be used only to retrieve data from a relational database.
B) The pandas method read_sql uses a Cursor behind the scenes to execute queries and access the rows of the results.
C) The INSERT INTO statement inserts a xe "row in a database table"row into a table.
D) The SQL keywords INSERT INTO are followed by the table in which to insert the new row and a comma-separated list of column names in parentheses.
Unlock Deck
Unlock for access to all 79 flashcards in this deck.
Unlock Deck
k this deck
16
Xe "author_ISBN table of books database"A goal when designing a relational database is to minimize data ________ among the tables.
A) dependency
B) binding
C) duplication
D) None of the above
A) dependency
B) binding
C) duplication
D) None of the above
Unlock Deck
Unlock for access to all 79 flashcards in this deck.
Unlock Deck
k this deck
17
Which of the following statements a), b) or c) is false?
A) Much of today's data is so large that it cannot fit on one system.
B) As big data grew, we needed distributed data storage and parallel processing capabilities to process vast amounts of data more efficiently. This led to complex technologies like xe "Hadoop (Apache)"xe "Apache Hadoop"Apache Hadoop for distributed data processing with massive parallelism among clusters of computers where the intricate details are handled for you automatically and correctly.
C) You can configure a multi-node Hadoop cluster using the Microsoft Azure HDInsight cloud service, then use it to execute a Hadoop MapReduce job implemented in Python.
D) All of the above statements are true.
A) Much of today's data is so large that it cannot fit on one system.
B) As big data grew, we needed distributed data storage and parallel processing capabilities to process vast amounts of data more efficiently. This led to complex technologies like xe "Hadoop (Apache)"xe "Apache Hadoop"Apache Hadoop for distributed data processing with massive parallelism among clusters of computers where the intricate details are handled for you automatically and correctly.
C) You can configure a multi-node Hadoop cluster using the Microsoft Azure HDInsight cloud service, then use it to execute a Hadoop MapReduce job implemented in Python.
D) All of the above statements are true.
Unlock Deck
Unlock for access to all 79 flashcards in this deck.
Unlock Deck
k this deck
18
In the SQL query: SELECT * FROM authors
The xe "* SQL wildcard character"asterisk (*) is a ________ indicating that the query should get all the columns from the authors table.
A) potpourri character
B) catchall
C) wildcard
D) None of the above
The xe "* SQL wildcard character"asterisk (*) is a ________ indicating that the query should get all the columns from the authors table.
A) potpourri character
B) catchall
C) wildcard
D) None of the above
Unlock Deck
Unlock for access to all 79 flashcards in this deck.
Unlock Deck
k this deck
19
Which of the following statements is false?
A) A database is an integrated collection of data.
B) Database management systems allow for convenient access and storage of data without concern for the internal representation of databases.
C) Rxe "relational database:relational database management system (RDBMS)"elational database management systems (RDBMSs) store data in xe ""tables and define relationships among the tables. xe "Structured Query Language (SQL)"
D) Table Query Language is used almost universally with relational database systems to manipulate data and perform queries, which request information that satisfies given criteria.
A) A database is an integrated collection of data.
B) Database management systems allow for convenient access and storage of data without concern for the internal representation of databases.
C) Rxe "relational database:relational database management system (RDBMS)"elational database management systems (RDBMSs) store data in xe ""tables and define relationships among the tables. xe "Structured Query Language (SQL)"
D) Table Query Language is used almost universally with relational database systems to manipulate data and perform queries, which request information that satisfies given criteria.
Unlock Deck
Unlock for access to all 79 flashcards in this deck.
Unlock Deck
k this deck
20
Which of the following statements a), b) or c) is false?
A) Each xe "column:in a database table"column in a relational database table represents a different data attribute.
B) Columns are unique (by primary key) within a table, but particular row values may be duplicated between columns.
C) Several rows in an Employee table's Department column could contain the same department number.
D) All of the above statements are true.
A) Each xe "column:in a database table"column in a relational database table represents a different data attribute.
B) Columns are unique (by primary key) within a table, but particular row values may be duplicated between columns.
C) Several rows in an Employee table's Department column could contain the same department number.
D) All of the above statements are true.
Unlock Deck
Unlock for access to all 79 flashcards in this deck.
Unlock Deck
k this deck
21
Which of the following statements a), b) or c) is false.
A) The types of applications that use NoSQL databases typically do not require the guarantees that ACID-compliant databases provide.
B) Many NoSQL databases typically adhere to the BASE (Basic Availability, Soft-state, Eventual consistency) model, which focuses more on the database's availability.
C) Whereas BASE databases guarantee consistency when you write to the database, ACID databases provide consistency at some later point in time.
D) All of the above statements are true.
A) The types of applications that use NoSQL databases typically do not require the guarantees that ACID-compliant databases provide.
B) Many NoSQL databases typically adhere to the BASE (Basic Availability, Soft-state, Eventual consistency) model, which focuses more on the database's availability.
C) Whereas BASE databases guarantee consistency when you write to the database, ACID databases provide consistency at some later point in time.
D) All of the above statements are true.
Unlock Deck
Unlock for access to all 79 flashcards in this deck.
Unlock Deck
k this deck
22
A ________ shades areas in a Folium map using the values you specify to determine color.
A) chromatic
B) choropleth
C) variagator
D) None of the above
A) chromatic
B) choropleth
C) variagator
D) None of the above
Unlock Deck
Unlock for access to all 79 flashcards in this deck.
Unlock Deck
k this deck
23
Which of the following statements a), b) or c) about Google's initial search implementation is false?
A) Google developed a clustering system, tying together vast numbers of inexpensive "commodity computers"-called nodes.
B) Because having more computers and more connections between them meant greater chance of hardware failures, Google also built in high levels of redundancy to ensure that the system would continue functioning even if nodes within clusters failed.
C) The data was distributed across all the inexpensive "commodity computers." To satisfy a search request, all the computers in the cluster searched in parallel the portion of the web they stored locally. Then the results of those searches were gathered up and reported back to the user.
D) All of the above statements are true.
A) Google developed a clustering system, tying together vast numbers of inexpensive "commodity computers"-called nodes.
B) Because having more computers and more connections between them meant greater chance of hardware failures, Google also built in high levels of redundancy to ensure that the system would continue functioning even if nodes within clusters failed.
C) The data was distributed across all the inexpensive "commodity computers." To satisfy a search request, all the computers in the cluster searched in parallel the portion of the web they stored locally. Then the results of those searches were gathered up and reported back to the user.
D) All of the above statements are true.
Unlock Deck
Unlock for access to all 79 flashcards in this deck.
Unlock Deck
k this deck
24
Which of the following statements a), b) or c) is false?
A) When Google was launched in 1998, there were approximately 2.4 million websites-truly big data at the time. Today there are now nearly two billion websites (almost a thousandfold increase since 1998).
B) When Google was developing their search engine, they knew that they needed to return search results quickly. The only practical way to do this was to store and index the entire Internet using a clever combination of secondary storage and main memory.
C) Popular computers of that time couldn't hold that amount of data and could not analyze that amount of data fast enough to guarantee prompt search-query responses.
D) All of the above statements are true.
A) When Google was launched in 1998, there were approximately 2.4 million websites-truly big data at the time. Today there are now nearly two billion websites (almost a thousandfold increase since 1998).
B) When Google was developing their search engine, they knew that they needed to return search results quickly. The only practical way to do this was to store and index the entire Internet using a clever combination of secondary storage and main memory.
C) Popular computers of that time couldn't hold that amount of data and could not analyze that amount of data fast enough to guarantee prompt search-query responses.
D) All of the above statements are true.
Unlock Deck
Unlock for access to all 79 flashcards in this deck.
Unlock Deck
k this deck
25
Which of the following statements a), b) or c) is false?
A) A document database stores xe "semi-structured data"semi-structured data, such as xe "JSON (JavaScript Object Notation)"JSON or xe "XML"XML documents.
B) In document databases, you typically add indexes for specific attributes, so you can more efficiently locate and manipulate documents.
C) The most popular document database (and most popular overall NoSQL database) is Neo4j.
D) All of the above statements are true.
A) A document database stores xe "semi-structured data"semi-structured data, such as xe "JSON (JavaScript Object Notation)"JSON or xe "XML"XML documents.
B) In document databases, you typically add indexes for specific attributes, so you can more efficiently locate and manipulate documents.
C) The most popular document database (and most popular overall NoSQL database) is Neo4j.
D) All of the above statements are true.
Unlock Deck
Unlock for access to all 79 flashcards in this deck.
Unlock Deck
k this deck
26
Which of the following statements a), b) or c) about graph databases is false?
A) A graph database models relationships between objects.
B) The objects are called nodes (or vertices) and the relationships are called edges.
C) Edges are bidirectional.
D) All of the above statements are true.
A) A graph database models relationships between objects.
B) The objects are called nodes (or vertices) and the relationships are called edges.
C) Edges are bidirectional.
D) All of the above statements are true.
Unlock Deck
Unlock for access to all 79 flashcards in this deck.
Unlock Deck
k this deck
27
Relational databases typically use ACID (Atomicity, xe "consistency"Consistency, Isolation, Durability) transactions. Which of the following ACID attributes is described by: "ensures that the database is modified only if all of a transaction's steps are successful?"
A) Atomicity
B) Consistency
C) Isolation
D) Durability
A) Atomicity
B) Consistency
C) Isolation
D) Durability
Unlock Deck
Unlock for access to all 79 flashcards in this deck.
Unlock Deck
k this deck
28
Which of the following statements a), b) or c) is false?
A) The four xe "NoSQL database"NoSQL database categories are xe "NoSQL database:key-value"xe "key-value:database[key value]"hierarchical, xe "NoSQL database:document database"xe "document database"document, xe "NoSQL database:columnar database"xe "columnar database (NoSQL)"columnar (also called xe "NoSQL database:column based "xe "columnar database (NoSQL):column-oriented database"column-based) and xe "NoSQL database:graph database"xe "graph database"graph.
B) NewSQL databases blend features of relational and NoSQL databases.
C) We presented a case study in which we stored and manipulated a large number of JSON tweet objects in a NoSQL document database, then summarized the data in an interactive visualization displayed on a Folium map of the United States.
D) All of the above statements are true.
A) The four xe "NoSQL database"NoSQL database categories are xe "NoSQL database:key-value"xe "key-value:database[key value]"hierarchical, xe "NoSQL database:document database"xe "document database"document, xe "NoSQL database:columnar database"xe "columnar database (NoSQL)"columnar (also called xe "NoSQL database:column based "xe "columnar database (NoSQL):column-oriented database"column-based) and xe "NoSQL database:graph database"xe "graph database"graph.
B) NewSQL databases blend features of relational and NoSQL databases.
C) We presented a case study in which we stored and manipulated a large number of JSON tweet objects in a NoSQL document database, then summarized the data in an interactive visualization displayed on a Folium map of the United States.
D) All of the above statements are true.
Unlock Deck
Unlock for access to all 79 flashcards in this deck.
Unlock Deck
k this deck
29
Which of the following statements a), b) or c) is false?
A) MongoDB is a document database capable of storing and retrieving JSON documents.
B) Twitter's APIs return tweets to you as xe "JSON (JavaScript Object Notation):object"JSON objects, which you can write directly into a MongoDB database.
C) MongoDB provides the free cloud-based MongoDB Atlas cluster for installation on your local computer.
D) All of the above statements are true.
A) MongoDB is a document database capable of storing and retrieving JSON documents.
B) Twitter's APIs return tweets to you as xe "JSON (JavaScript Object Notation):object"JSON objects, which you can write directly into a MongoDB database.
C) MongoDB provides the free cloud-based MongoDB Atlas cluster for installation on your local computer.
D) All of the above statements are true.
Unlock Deck
Unlock for access to all 79 flashcards in this deck.
Unlock Deck
k this deck
30
Relational databases typically use ACID (Atomicity, xe "consistency"Consistency, Isolation, Durability) transactions. Which of the following ACID attributes is described by: "ensures that concurrent transactions occur as if they were performed sequentially?"
A) Atomicity
B) Consistency
C) Isolation
D) Durability
A) Atomicity
B) Consistency
C) Isolation
D) Durability
Unlock Deck
Unlock for access to all 79 flashcards in this deck.
Unlock Deck
k this deck
31
Which of the following statements a), b) or c) is false?
A) A graph database stores nodes, edges and their attributes. If you use social networks, like Instagram, Snapchat, Twitter and Facebook, consider your xe "social graph"social graph, which consists of the people you know (nodes) and the relationships between them (edges). Every person has their own social graph, and these are interconnected.
B) The famous "six degrees of separation" problem says that any two people in the world are connected to one another by following a maximum of six edges in the worldwide social graph.
C) Facebook's algorithms use the social graphs of their billions of users to determine which stories should appear in each user's news feed.
D) All of the above statements are true.
A) A graph database stores nodes, edges and their attributes. If you use social networks, like Instagram, Snapchat, Twitter and Facebook, consider your xe "social graph"social graph, which consists of the people you know (nodes) and the relationships between them (edges). Every person has their own social graph, and these are interconnected.
B) The famous "six degrees of separation" problem says that any two people in the world are connected to one another by following a maximum of six edges in the worldwide social graph.
C) Facebook's algorithms use the social graphs of their billions of users to determine which stories should appear in each user's news feed.
D) All of the above statements are true.
Unlock Deck
Unlock for access to all 79 flashcards in this deck.
Unlock Deck
k this deck
32
Which of the following statements is false?
A) Pandas DataFrame method groupby groups data by a specified column's values, as in:
Tweets_counts_by_state = tweet_counts_df.groupby(
'State', as_index=False).sum()
B) The as_index=False keyword argument in Part (a) indicates that the values on which grouping was performed ('State' in this case) should be values in a row of the resulting GroupBy object, rather than the indices for the columns.
C) The GroupBy object's sum method, which is called at the end of the snippet in Part (a), totals the GroupBy object's numeric data by 'State'.
D) All of the above statements are true.
A) Pandas DataFrame method groupby groups data by a specified column's values, as in:
Tweets_counts_by_state = tweet_counts_df.groupby(
'State', as_index=False).sum()
B) The as_index=False keyword argument in Part (a) indicates that the values on which grouping was performed ('State' in this case) should be values in a row of the resulting GroupBy object, rather than the indices for the columns.
C) The GroupBy object's sum method, which is called at the end of the snippet in Part (a), totals the GroupBy object's numeric data by 'State'.
D) All of the above statements are true.
Unlock Deck
Unlock for access to all 79 flashcards in this deck.
Unlock Deck
k this deck
33
Which of the following statements a), b) or c) is false?
A) Like Python dictionaries, key-value databases store key-value pairs, but they're optimized for distributed systems and big-data processing.
B) For performance, key-value databases tend to replicate data in multiple cluster nodes.
C) Some key-value databases are implemented in memory for performance, and others store data on disk.
D) All of the above statements are true.
A) Like Python dictionaries, key-value databases store key-value pairs, but they're optimized for distributed systems and big-data processing.
B) For performance, key-value databases tend to replicate data in multiple cluster nodes.
C) Some key-value databases are implemented in memory for performance, and others store data on disk.
D) All of the above statements are true.
Unlock Deck
Unlock for access to all 79 flashcards in this deck.
Unlock Deck
k this deck
34
Which of the following statements about text searching in MongoDB is false?
A) To xe "MongoDB document database:text search"xe "text search"text search in MongoDB, you must create a xe "MongoDB document database:text index"xe "text index"text index for the collection. This specifies which document field(s) to search.
B) Each text index is defined as a tuple containing the field name to search and the index type ('text_index').
C) MongoDB's xe "MongoDB document database:wildcard specifier ($**)"xe "wildcard specifier ($**)"wildcard specifier $** indicates that every text field in a document should be indexed for a full-text search.
D) Once an index is defined for a Collection, you can use its count_documents method to count the total number of documents in the collection that contain the specified text.
A) To xe "MongoDB document database:text search"xe "text search"text search in MongoDB, you must create a xe "MongoDB document database:text index"xe "text index"text index for the collection. This specifies which document field(s) to search.
B) Each text index is defined as a tuple containing the field name to search and the index type ('text_index').
C) MongoDB's xe "MongoDB document database:wildcard specifier ($**)"xe "wildcard specifier ($**)"wildcard specifier $** indicates that every text field in a document should be indexed for a full-text search.
D) Once an index is defined for a Collection, you can use its count_documents method to count the total number of documents in the collection that contain the specified text.
Unlock Deck
Unlock for access to all 79 flashcards in this deck.
Unlock Deck
k this deck
35
Which of the following statements a), b) or c) is false?
A) To store tweets' JSON as documents in a MongoDB database, you must first connect to your MongoDB Atlas cluster via a pymongo MongoClient, which receives your cluster's xe "connection string (MongoDB)"connection string as its argument, as in:
From pymongo import MongoClient
Atlas_client = MongoClient(keys.mongo_connection_string)
B) The following code uses a pymongo MongoClient to get a pymongo Database object representing a senators database, creating the database if it does not exist:
Db = atlas_client.senators
C) Before storing JSON objects in a collection of a MongoDB database, you must explicitly create the collection.
D) All of the above statements are true.
A) To store tweets' JSON as documents in a MongoDB database, you must first connect to your MongoDB Atlas cluster via a pymongo MongoClient, which receives your cluster's xe "connection string (MongoDB)"connection string as its argument, as in:
From pymongo import MongoClient
Atlas_client = MongoClient(keys.mongo_connection_string)
B) The following code uses a pymongo MongoClient to get a pymongo Database object representing a senators database, creating the database if it does not exist:
Db = atlas_client.senators
C) Before storing JSON objects in a collection of a MongoDB database, you must explicitly create the collection.
D) All of the above statements are true.
Unlock Deck
Unlock for access to all 79 flashcards in this deck.
Unlock Deck
k this deck
36
________ your IP address is a MongoDB security measure which ensures that only IP addresses you verify are allowed to interact with your MongoDB Atlas cluster.
A) Blocking
B) Blacklisting
C) Whitelisting
D) None of the above.
A) Blocking
B) Blacklisting
C) Whitelisting
D) None of the above.
Unlock Deck
Unlock for access to all 79 flashcards in this deck.
Unlock Deck
k this deck
37
The following code loads senators.csv into a ________. import pandas as pd
Senators_df = pd.read_csv('senators.csv')
A) NumPy two-dimensional array
B) two-dimensional list
C) pandas DataFrame
D) dictionary
Senators_df = pd.read_csv('senators.csv')
A) NumPy two-dimensional array
B) two-dimensional list
C) pandas DataFrame
D) dictionary
Unlock Deck
Unlock for access to all 79 flashcards in this deck.
Unlock Deck
k this deck
38
YouTube videos including the associated metadata are ________ data.
A) semi-structured
B) structured
C) unstructured
D) None of the above
A) semi-structured
B) structured
C) unstructured
D) None of the above
Unlock Deck
Unlock for access to all 79 flashcards in this deck.
Unlock Deck
k this deck
39
Which of the following statements about columnar databases a), b) or c) is false?
A) A columnar database is similar to a relational database, but it stores unstructured data in columns rather than rows.
B) Because all of a column's elements are stored together, selecting all the data for a given column is more efficient.
C) Consider our authors table in the books database: first last
Id
1 Paul Deitel
2 Harvey Deitel
3 Abbey Deitel
4 Dan Quirk
5 Alexander Wald
If we consider each row as a Python tuple, the rows would be represented as (1, 'Paul', 'Deitel'), (2, 'Harvey', 'Deitel'), etc. In a columnar database, all the values for a given column would be stored together, as in (1, 2, 3, 4, 5), ('Paul', 'Harvey', 'Abbey', 'Dan', 'Alexander') and ('Deitel', 'Deitel', 'Deitel', 'Quirk', 'Wald').
D) All of the above statements are true.
A) A columnar database is similar to a relational database, but it stores unstructured data in columns rather than rows.
B) Because all of a column's elements are stored together, selecting all the data for a given column is more efficient.
C) Consider our authors table in the books database: first last
Id
1 Paul Deitel
2 Harvey Deitel
3 Abbey Deitel
4 Dan Quirk
5 Alexander Wald
If we consider each row as a Python tuple, the rows would be represented as (1, 'Paul', 'Deitel'), (2, 'Harvey', 'Deitel'), etc. In a columnar database, all the values for a given column would be stored together, as in (1, 2, 3, 4, 5), ('Paul', 'Harvey', 'Abbey', 'Dan', 'Alexander') and ('Deitel', 'Deitel', 'Deitel', 'Quirk', 'Wald').
D) All of the above statements are true.
Unlock Deck
Unlock for access to all 79 flashcards in this deck.
Unlock Deck
k this deck
40
A JSON dialect called ________ describes the boundaries of shapes such as countries, states, etc. for use in maps.
A) BoundaryJSON
B) GeoJSON
C) TopographyJSON
D) None of the above
A) BoundaryJSON
B) GeoJSON
C) TopographyJSON
D) None of the above
Unlock Deck
Unlock for access to all 79 flashcards in this deck.
Unlock Deck
k this deck
41
Consider the following reducer code: 1 #!/usr/bin/env python3
2 # length_reducer.py
3 """Counts the number of words with each length."""
4 import sys
5 from itertools import groupby
6 from operator import itemgetter
7
8 def tokenize_input():
9 """Split each line of standard input into a key and a value."""
10 for line in sys.stdin:
11 yield line.strip().split('\t')
12
13 # produce key-value pairs of word lengths and counts separated by tabs
14 for word_length, group in groupby(tokenize_input(), itemgetter(0)):
15 try:
16 total = sum(int(count) for word_length, count in group)
17 print(word_length + '\t' + str(total))
18 except ValueError:
19 pass # ignore word if its count was not an integer
Which of the following statements a), b) or c) is false?
A) When the MapReduce algorithm executes this reducer, lines 14-19 use the groupby function from the itertools module to group all word lengths of the same value. The first argument calls tokenize_input to get the lists representing the key-value pairs. The second argument indicates that the key-value pairs should be grouped based on the element at index 0 in each list-that is the key.
B) Line 16 totals all the counts for a given key. Line 17 outputs a new key-value pair consisting of the word length and the total number of words of that length.
C) The MapReduce algorithm takes all the final word length and count outputs and writes them to a file in HDFS-the Hadoop file system.
D) All of the above statements are true.
2 # length_reducer.py
3 """Counts the number of words with each length."""
4 import sys
5 from itertools import groupby
6 from operator import itemgetter
7
8 def tokenize_input():
9 """Split each line of standard input into a key and a value."""
10 for line in sys.stdin:
11 yield line.strip().split('\t')
12
13 # produce key-value pairs of word lengths and counts separated by tabs
14 for word_length, group in groupby(tokenize_input(), itemgetter(0)):
15 try:
16 total = sum(int(count) for word_length, count in group)
17 print(word_length + '\t' + str(total))
18 except ValueError:
19 pass # ignore word if its count was not an integer
Which of the following statements a), b) or c) is false?
A) When the MapReduce algorithm executes this reducer, lines 14-19 use the groupby function from the itertools module to group all word lengths of the same value. The first argument calls tokenize_input to get the lists representing the key-value pairs. The second argument indicates that the key-value pairs should be grouped based on the element at index 0 in each list-that is the key.
B) Line 16 totals all the counts for a given key. Line 17 outputs a new key-value pair consisting of the word length and the total number of words of that length.
C) The MapReduce algorithm takes all the final word length and count outputs and writes them to a file in HDFS-the Hadoop file system.
D) All of the above statements are true.
Unlock Deck
Unlock for access to all 79 flashcards in this deck.
Unlock Deck
k this deck
42
Which of the following statements a), b) or c) is false?
A) For high-performance, Spark distributes the operations you specify in Python to the cluster's nodes for parallel execution. xe "Spark (Apache):streaming"Spark streaming enables you to process data as it's received.
B) Pandas DataFrames enable you to view RDDs as a collection of named columns. You can use pandas DataFrames with Spark SQL to perform queries on distributed data.
C) Spark also includes Spark MLlib (the Spark Machine Learning Library), which enables you to perform machine-learning algorithms.
D) All of the above statements are true.
A) For high-performance, Spark distributes the operations you specify in Python to the cluster's nodes for parallel execution. xe "Spark (Apache):streaming"Spark streaming enables you to process data as it's received.
B) Pandas DataFrames enable you to view RDDs as a collection of named columns. You can use pandas DataFrames with Spark SQL to perform queries on distributed data.
C) Spark also includes Spark MLlib (the Spark Machine Learning Library), which enables you to perform machine-learning algorithms.
D) All of the above statements are true.
Unlock Deck
Unlock for access to all 79 flashcards in this deck.
Unlock Deck
k this deck
43
Which Hadoop ecosystem technology is described by "A service for managing cluster configurations and coordination between clusters?"
A) Sqoop
B) Storm
C) ZooKeeper
D) None of the above
A) Sqoop
B) Storm
C) ZooKeeper
D) None of the above
Unlock Deck
Unlock for access to all 79 flashcards in this deck.
Unlock Deck
k this deck
44
Hadoop streaming uses the standard input and standard output streams as follows:
A) Hadoop supplies the input to the mapping script-called the mapper. This script reads its input from the standard input stream. The mapper writes its results to the standard output stream.
B) Hadoop supplies the mapper's output as the input to the reduction script-called the reducer-which reads from the standard input stream.
C) The reducer writes its results to the standard output stream. Hadoop writes the reducer's output to the Hadoop file system (HDFS).
D) All of the above statements are true.
A) Hadoop supplies the input to the mapping script-called the mapper. This script reads its input from the standard input stream. The mapper writes its results to the standard output stream.
B) Hadoop supplies the mapper's output as the input to the reduction script-called the reducer-which reads from the standard input stream.
C) The reducer writes its results to the standard output stream. Hadoop writes the reducer's output to the Hadoop file system (HDFS).
D) All of the above statements are true.
Unlock Deck
Unlock for access to all 79 flashcards in this deck.
Unlock Deck
k this deck
45
Which of the following statements about MapReduce is false
A) In the MapReduce step, Hadoop divides the data into batches that it distributes across the nodes in the cluster.
B) Hadoop also distributes the MapReduce task's code to the nodes in the cluster and executes the code on one node at a time sequentially. Each node processes only the batch of data stored on that node.
C) The reduction step combines the results from all the nodes to produce the final result.
D) To coordinate all this, Hadoop uses YARN ("yet another resource negotiator") to manage all the resources in the cluster and schedule tasks for execution.
A) In the MapReduce step, Hadoop divides the data into batches that it distributes across the nodes in the cluster.
B) Hadoop also distributes the MapReduce task's code to the nodes in the cluster and executes the code on one node at a time sequentially. Each node processes only the batch of data stored on that node.
C) The reduction step combines the results from all the nodes to produce the final result.
D) To coordinate all this, Hadoop uses YARN ("yet another resource negotiator") to manage all the resources in the cluster and schedule tasks for execution.
Unlock Deck
Unlock for access to all 79 flashcards in this deck.
Unlock Deck
k this deck
46
Consider the following reducer code: 1 #!/usr/bin/env python3
2 # length_reducer.py
3 """Counts the number of words with each length."""
4 import sys
5 from itertools import groupby
6 from operator import itemgetter
7
8 def tokenize_input():
9 """Split each line of standard input into a key and a value."""
10 for line in sys.stdin:
11 yield line.strip().split('\t')
12
13 # produce key-value pairs of word lengths and counts separated by tabs
14 for word_length, group in groupby(tokenize_input(), itemgetter(0)):
15 try:
16 total = sum(int(count) for word_length, count in group)
17 print(word_length + '\t' + str(total))
18 except ValueError:
19 pass # ignore word if its count was not an integer
Which of the following statements a), b) or c) is false?
A) Function tokenize_input is a generator function that reads and splits the key-value pairs produced by the mapper.
B) The mapper script sends its output directly to the reducer script.
C) For each line, tokenize_input strips any leading or trailing whitespace (such as the terminating newline) and yields a list containing the key and a value.
D) All of the above statements are true.
2 # length_reducer.py
3 """Counts the number of words with each length."""
4 import sys
5 from itertools import groupby
6 from operator import itemgetter
7
8 def tokenize_input():
9 """Split each line of standard input into a key and a value."""
10 for line in sys.stdin:
11 yield line.strip().split('\t')
12
13 # produce key-value pairs of word lengths and counts separated by tabs
14 for word_length, group in groupby(tokenize_input(), itemgetter(0)):
15 try:
16 total = sum(int(count) for word_length, count in group)
17 print(word_length + '\t' + str(total))
18 except ValueError:
19 pass # ignore word if its count was not an integer
Which of the following statements a), b) or c) is false?
A) Function tokenize_input is a generator function that reads and splits the key-value pairs produced by the mapper.
B) The mapper script sends its output directly to the reducer script.
C) For each line, tokenize_input strips any leading or trailing whitespace (such as the terminating newline) and yields a list containing the key and a value.
D) All of the above statements are true.
Unlock Deck
Unlock for access to all 79 flashcards in this deck.
Unlock Deck
k this deck
47
Which of the following statements a), b) or c) is false?
A) For languages like Python that are not natively supported in Hadoop, you must use Hadoop streaming to implement your tasks.
B) In Hadoop streaming, the Python scripts that implement the mapping and reduction steps use network sockets to communicate with Hadoop.
C) Usually, the standard input stream reads from the keyboard and the standard output stream writes to the command line. However, these can be redirected (as Hadoop does) to read from other sources and write to other destinations.
D) All of the above statements are true.
A) For languages like Python that are not natively supported in Hadoop, you must use Hadoop streaming to implement your tasks.
B) In Hadoop streaming, the Python scripts that implement the mapping and reduction steps use network sockets to communicate with Hadoop.
C) Usually, the standard input stream reads from the keyboard and the standard output stream writes to the command line. However, these can be redirected (as Hadoop does) to read from other sources and write to other destinations.
D) All of the above statements are true.
Unlock Deck
Unlock for access to all 79 flashcards in this deck.
Unlock Deck
k this deck
48
Which of the following statements a), b) or c) is false?
A) Docker is a tool for packaging software into containers that bundle everything required to execute that software across platforms.
B) Some software packages require complicated setup and configuration. For many of these, there are preexisting Docker containers that you can download for free and execute locally on your desktop or notebook computers.
C) You can create custom Docker containers that are configured with the versions of every piece of software and every library you used in your study. This would enable others to recreate the environment you used, then reproduce your work, and will help you reproduce your results at a later time.
D) All of the above statements are true.
A) Docker is a tool for packaging software into containers that bundle everything required to execute that software across platforms.
B) Some software packages require complicated setup and configuration. For many of these, there are preexisting Docker containers that you can download for free and execute locally on your desktop or notebook computers.
C) You can create custom Docker containers that are configured with the versions of every piece of software and every library you used in your study. This would enable others to recreate the environment you used, then reproduce your work, and will help you reproduce your results at a later time.
D) All of the above statements are true.
Unlock Deck
Unlock for access to all 79 flashcards in this deck.
Unlock Deck
k this deck
49
Which of the following statements a), b) or c) is false?
A) When you process truly big data, performance is crucial.
B) Spark is geared to disk-based batch processing-reading the data from disk, processing the data and writing the results back to disk.
C) Many big-data applications demand better performance than is possible with disk-intensive operations. In particular, fast streaming applications that require either real-time or near-real-time processing won't work in a disk-based architecture.
D) All of the above statements are true.
A) When you process truly big data, performance is crucial.
B) Spark is geared to disk-based batch processing-reading the data from disk, processing the data and writing the results back to disk.
C) Many big-data applications demand better performance than is possible with disk-intensive operations. In particular, fast streaming applications that require either real-time or near-real-time processing won't work in a disk-based architecture.
D) All of the above statements are true.
Unlock Deck
Unlock for access to all 79 flashcards in this deck.
Unlock Deck
k this deck
50
Which Hadoop ecosystem technology is described by "SQL querying of non-relational data in Hadoop and NoSQL databases."
A) Ambari
B) Drill
C) Flume
D) HBase
A) Ambari
B) Drill
C) Flume
D) HBase
Unlock Deck
Unlock for access to all 79 flashcards in this deck.
Unlock Deck
k this deck
51
Which of the following statements is false?
A) To develop its initial search implementation, Google needed to develop the clustering hardware and software, including distributed storage.
B) Google published its designs in the research paper "The Google File System," but did not open source its software.
C) Programmers at Yahoo!, working from Google's designs in the "Google File System" paper, then built their own system.
D) Yahoo! open-sourced their work and the Eclipse Foundation implemented the system as Hadoop.
A) To develop its initial search implementation, Google needed to develop the clustering hardware and software, including distributed storage.
B) Google published its designs in the research paper "The Google File System," but did not open source its software.
C) Programmers at Yahoo!, working from Google's designs in the "Google File System" paper, then built their own system.
D) Yahoo! open-sourced their work and the Eclipse Foundation implemented the system as Hadoop.
Unlock Deck
Unlock for access to all 79 flashcards in this deck.
Unlock Deck
k this deck
52
Which of the following Hadoop ecosystem technologies is described by "real-time messaging, stream processing and storage, typically to transform and process high-volume streaming data, such as website activity and streaming IoT data."
A) Hive
B) Impala
C) Kafka
D) Pig
A) Hive
B) Impala
C) Kafka
D) Pig
Unlock Deck
Unlock for access to all 79 flashcards in this deck.
Unlock Deck
k this deck
53
Which of the following statements a), b) or c) is false?
A) By default, Hadoop expects the mapper's output and the reducer's input and output to be in the form of key-value pairs separated by a tab.
B) In a mapper script, the notation #!/usr/bin/env python3 tells Hadoop to execute the Python code using python3. This line must come before all other comments and code in the file.
C) At the time of this writing, Microsoft HDInsight clusters contain Python 2.7.12 and Python 3.5.2, so you can use f-strings in your code.
D) All of the above statements are true.
A) By default, Hadoop expects the mapper's output and the reducer's input and output to be in the form of key-value pairs separated by a tab.
B) In a mapper script, the notation #!/usr/bin/env python3 tells Hadoop to execute the Python code using python3. This line must come before all other comments and code in the file.
C) At the time of this writing, Microsoft HDInsight clusters contain Python 2.7.12 and Python 3.5.2, so you can use f-strings in your code.
D) All of the above statements are true.
Unlock Deck
Unlock for access to all 79 flashcards in this deck.
Unlock Deck
k this deck
54
Which of the following statements is false?
A) Two key Hadoop components are HDFS (Hadoop Distributed File System) for storing massive amounts of data throughout a cluster, and MapReduce for implementing the tasks that process the data.
B) Hadoop MapReduce is similar in concept to the functional-style programming, just on a xe "massively parallel processing"massively parallel scale.
C) A MapReduce task performs two steps-mapping and reduction.
D) The mapping step processes the original data across the entire cluster and maps it into tuples of key-value pairs. The reduction step, which also may include filtering, then combines those tuples to produce the results of the MapReduce task.
A) Two key Hadoop components are HDFS (Hadoop Distributed File System) for storing massive amounts of data throughout a cluster, and MapReduce for implementing the tasks that process the data.
B) Hadoop MapReduce is similar in concept to the functional-style programming, just on a xe "massively parallel processing"massively parallel scale.
C) A MapReduce task performs two steps-mapping and reduction.
D) The mapping step processes the original data across the entire cluster and maps it into tuples of key-value pairs. The reduction step, which also may include filtering, then combines those tuples to produce the results of the MapReduce task.
Unlock Deck
Unlock for access to all 79 flashcards in this deck.
Unlock Deck
k this deck
55
Which of the following statements a), b) or c) is false?
A) Most major cloud vendors have support for Hadoop and Spark computing clusters that you can configure to meet your application's requirements.
B) Multi-node cloud-based clusters typically are free services.
C) Microsoft Azure's HDInsight service provides Hadoop capabilities.
D) All of the above statements are true.
A) Most major cloud vendors have support for Hadoop and Spark computing clusters that you can configure to meet your application's requirements.
B) Multi-node cloud-based clusters typically are free services.
C) Microsoft Azure's HDInsight service provides Hadoop capabilities.
D) All of the above statements are true.
Unlock Deck
Unlock for access to all 79 flashcards in this deck.
Unlock Deck
k this deck
56
Which of the following statements is false?
A) Spark was initially developed in 2009 at U. C. Berkeley and funded by xe "DARPA (the Defense Advanced Research Projects Agency)"DARPA (the Defense Advanced Research Projects Agency).
B) Spark was created as a distributed execution engine for high-performance natural language processing.
C) Spark uses an in-memory architecture that "has been used to sort 100 TB of data 3X faster than Hadoop MapReduce on 1/10th of the machines" and runs some workloads up to 100 times faster than Hadoop.
D) Spark's significantly better performance on batch-processing tasks is leading many companies to replace Hadoop MapReduce with Spark.
A) Spark was initially developed in 2009 at U. C. Berkeley and funded by xe "DARPA (the Defense Advanced Research Projects Agency)"DARPA (the Defense Advanced Research Projects Agency).
B) Spark was created as a distributed execution engine for high-performance natural language processing.
C) Spark uses an in-memory architecture that "has been used to sort 100 TB of data 3X faster than Hadoop MapReduce on 1/10th of the machines" and runs some workloads up to 100 times faster than Hadoop.
D) Spark's significantly better performance on batch-processing tasks is leading many companies to replace Hadoop MapReduce with Spark.
Unlock Deck
Unlock for access to all 79 flashcards in this deck.
Unlock Deck
k this deck
57
Consider the following mapper code: 1 #!/usr/bin/env python3
2 # length_mapper.py
3 """Maps lines of text to key-value pairs of word lengths and 1."""
4 import sys
5
6 def tokenize_input():
7 """Split each line of standard input into a list of strings."""
8 for line in sys.stdin:
9 yield line.split()
10
11 # read each line in the the standard input and for every word
12 # produce a key-value pair containing the word, a tab and 1
13 for line in tokenize_input():
14 for word in line:
15 print(str(len(word)) + '\t1')
Which of the following statements a), b) or c) is false.
A) Generator function tokenize_input reads lines of text from the standard input stream and for each returns a list of strings.
B) When Hadoop executes the script, lines 13-15 iterate through the lists of strings from tokenize_input. For each list (line) and for every string (word) in that list, the script outputs a key-value pair with the word's length as the key, a tab (\t) and the value 1, indicating that there is one word (so far) of that length. Of course, there probably are many words of that length.
C) The MapReduce algorithm's reduction step will summarize these key-value pairs.
D) All of the above statements are true.
2 # length_mapper.py
3 """Maps lines of text to key-value pairs of word lengths and 1."""
4 import sys
5
6 def tokenize_input():
7 """Split each line of standard input into a list of strings."""
8 for line in sys.stdin:
9 yield line.split()
10
11 # read each line in the the standard input and for every word
12 # produce a key-value pair containing the word, a tab and 1
13 for line in tokenize_input():
14 for word in line:
15 print(str(len(word)) + '\t1')
Which of the following statements a), b) or c) is false.
A) Generator function tokenize_input reads lines of text from the standard input stream and for each returns a list of strings.
B) When Hadoop executes the script, lines 13-15 iterate through the lists of strings from tokenize_input. For each list (line) and for every string (word) in that list, the script outputs a key-value pair with the word's length as the key, a tab (\t) and the value 1, indicating that there is one word (so far) of that length. Of course, there probably are many words of that length.
C) The MapReduce algorithm's reduction step will summarize these key-value pairs.
D) All of the above statements are true.
Unlock Deck
Unlock for access to all 79 flashcards in this deck.
Unlock Deck
k this deck
58
Which of the following statements a), b) or c) is false?
A) Every time you start a container with docker run, Docker gives you a new instance that contains any libraries you installed previously.
B) The command docker stop container_name
Will shut down the specified container. The command
Docker restart container_name
Will restart the specified container.
C) Docker also provides a GUI app called xe "Kitematic (Docker GUI app)"Kitematic that you can use to manage your containers, including stopping and restarting them.
D) All of the above statements are true.
A) Every time you start a container with docker run, Docker gives you a new instance that contains any libraries you installed previously.
B) The command docker stop container_name
Will shut down the specified container. The command
Docker restart container_name
Will restart the specified container.
C) Docker also provides a GUI app called xe "Kitematic (Docker GUI app)"Kitematic that you can use to manage your containers, including stopping and restarting them.
D) All of the above statements are true.
Unlock Deck
Unlock for access to all 79 flashcards in this deck.
Unlock Deck
k this deck
59
Which of the following statements a), b) or c) is false?
A) Hadoop providers typically also provide Spark support.
B) Databricks is a Spark-specific vendor-they provide a "zero-management cloud platform built around Spark." Their website also is an excellent resource for learning Spark.
C) The paid Databricks platform runs on Amazon AWS or Microsoft Azure. Databricks also provides a free Databricks Community Edition, which is a great way to get started with both Spark and the Databricks environment.
D) All of the above statements are true.
A) Hadoop providers typically also provide Spark support.
B) Databricks is a Spark-specific vendor-they provide a "zero-management cloud platform built around Spark." Their website also is an excellent resource for learning Spark.
C) The paid Databricks platform runs on Amazon AWS or Microsoft Azure. Databricks also provides a free Databricks Community Edition, which is a great way to get started with both Spark and the Databricks environment.
D) All of the above statements are true.
Unlock Deck
Unlock for access to all 79 flashcards in this deck.
Unlock Deck
k this deck
60
Which of the following statements a), b) or c) is false?
A) Numerous cloud vendors provide Hadoop as a service.
B) In addition, companies like xe "Cloudera CDH"Cloudera and xe "Hortonworks"Hortonworks (recently merged) offer integrated Hadoop-ecosystem components and tools via the major cloud vendors.
C) Cloudera and xe "Hortonworks"Hortonworks also offer free downloadable environments that you can run on the desktop for learning, development and testing before you commit to cloud-based hosting, which can incur significant costs.
D) All of the above statements are true.
A) Numerous cloud vendors provide Hadoop as a service.
B) In addition, companies like xe "Cloudera CDH"Cloudera and xe "Hortonworks"Hortonworks (recently merged) offer integrated Hadoop-ecosystem components and tools via the major cloud vendors.
C) Cloudera and xe "Hortonworks"Hortonworks also offer free downloadable environments that you can run on the desktop for learning, development and testing before you commit to cloud-based hosting, which can incur significant costs.
D) All of the above statements are true.
Unlock Deck
Unlock for access to all 79 flashcards in this deck.
Unlock Deck
k this deck
61
Which of the following statements is false?
A) You can use SQL to query data in xe "resilient distributed dataset (RDD)"resilient distributed datasets (RDDs).
B) Spark SQL uses a Spark DataFrame to get a table view of the underlying RDDs.
C) A SparkSession (module pyspark.sql) is used to create a xe "DataFrame (Spark)"xe "modules:pyspark.sql"xe "pyspark.sql module"xe "modules:pyspark.sql"xe "DataFrame (Spark):pyspark.sql module"DataFrame from an xe ""RDD. There can be only one SparkSession object per Spark application.
D) In Spark streaming, a DStream is a sequence of xe "RDD (resilient distributed dataset)"xe "resilient distributed dataset (RDD)"RDDs each representing a mini-batch of data to process
A) You can use SQL to query data in xe "resilient distributed dataset (RDD)"resilient distributed datasets (RDDs).
B) Spark SQL uses a Spark DataFrame to get a table view of the underlying RDDs.
C) A SparkSession (module pyspark.sql) is used to create a xe "DataFrame (Spark)"xe "modules:pyspark.sql"xe "pyspark.sql module"xe "modules:pyspark.sql"xe "DataFrame (Spark):pyspark.sql module"DataFrame from an xe ""RDD. There can be only one SparkSession object per Spark application.
D) In Spark streaming, a DStream is a sequence of xe "RDD (resilient distributed dataset)"xe "resilient distributed dataset (RDD)"RDDs each representing a mini-batch of data to process
Unlock Deck
Unlock for access to all 79 flashcards in this deck.
Unlock Deck
k this deck
62
Which of the following statements a), b) or c) is false?
A) In the late 1960s, the Internet began as the xe "ARPANET"ARPANET, which initially connected four universities and grew to 10 nodes by the end of 1970.
B) In the last 50 years, the Internet has grown to billions of computers, smartphones, tablets and an enormous range of other device types connected to the Internet worldwide.
C) Every device is a "thing" in the xe "IoT (Internet of Things)"xe "Internet of Things (IoT)"Internet of Things (IoT).
D) All of the above statements are true.
A) In the late 1960s, the Internet began as the xe "ARPANET"ARPANET, which initially connected four universities and grew to 10 nodes by the end of 1970.
B) In the last 50 years, the Internet has grown to billions of computers, smartphones, tablets and an enormous range of other device types connected to the Internet worldwide.
C) Every device is a "thing" in the xe "IoT (Internet of Things)"xe "Internet of Things (IoT)"Internet of Things (IoT).
D) All of the above statements are true.
Unlock Deck
Unlock for access to all 79 flashcards in this deck.
Unlock Deck
k this deck
63
Every RDD has access to the current SparkContext via the attribute ________.
A) cluster
B) broadcast
C) context
D) connection
A) cluster
B) broadcast
C) context
D) connection
Unlock Deck
Unlock for access to all 79 flashcards in this deck.
Unlock Deck
k this deck
64
The following dashboard visualizes simulated sensors from the PubNub simulated IoT sensors stream: For each sensor, the visualization shows a Gauge (the semicircular visualizations) and a ________ (the jagged lines) to visualize the data.
A) Sparkleline
B) Glowline
C) Sparkline
D) None of the above
For each sensor, the visualization shows a Gauge (the semicircular visualizations) and a ________ (the jagged lines) to visualize the data.A) Sparkleline
B) Glowline
C) Sparkline
D) None of the above
Unlock Deck
Unlock for access to all 79 flashcards in this deck.
Unlock Deck
k this deck
65
When you subscribe to a PubNub stream, you must add a(n) ________ that receives status notifications and messages from the channel.
A) acceptor
B) auditor
C) listener
D) None of the above
A) acceptor
B) auditor
C) listener
D) None of the above
Unlock Deck
Unlock for access to all 79 flashcards in this deck.
Unlock Deck
k this deck
66
Which of the following statements a), b) or c) is false?
A) The following code calls a socket object's bind method with a tuple containing the xe "hostname"hostname or xe "IP address"IP address of the computer and the port number on that computer. Together these represent where an app should wait for an initial connection from another app:
Client_socket.bind(('localhost', 9876))
B) A socket's listen method causes the script to wait until a connection is received, as in:
Client_socket.listen() # wait for client to connect
C) Once a client application connects, socket method accept accepts the connection. This method returns a tuple containing a new socket object that the script will use to communicate with the client application and the IP address of the client application's computer.
Connection, address = client_socket.accept()
D) All of the above statements are true.
A) The following code calls a socket object's bind method with a tuple containing the xe "hostname"hostname or xe "IP address"IP address of the computer and the port number on that computer. Together these represent where an app should wait for an initial connection from another app:
Client_socket.bind(('localhost', 9876))
B) A socket's listen method causes the script to wait until a connection is received, as in:
Client_socket.listen() # wait for client to connect
C) Once a client application connects, socket method accept accepts the connection. This method returns a tuple containing a new socket object that the script will use to communicate with the client application and the IP address of the client application's computer.
Connection, address = client_socket.accept()
D) All of the above statements are true.
Unlock Deck
Unlock for access to all 79 flashcards in this deck.
Unlock Deck
k this deck
67
StreamingContext's ________ method begins the streaming process.
A) stream
B) start
C) start_stream
D) None of the above
A) stream
B) start
C) start_stream
D) None of the above
Unlock Deck
Unlock for access to all 79 flashcards in this deck.
Unlock Deck
k this deck
68
Which of the following statements a), b) or c) is false?
A) IoT devices (and many other types of devices and applications) commonly communicate with one another and with applications via pub/sub (publisher/subscriber) systems.
B) A publisher is any device or application that sends a message to a cloud-based service, which in turn sends that message to all subscribers. Typically each publisher specifies a topic or channel, and each subscriber specifies one or more topics or channels for which they'd like to receive messages.
C) Apache Kafka is a Hadoop ecosystem component that provides a high-performance publish/subscribe service, real-time stream processing and storage of streamed data.
D) All of the above statements are true.
A) IoT devices (and many other types of devices and applications) commonly communicate with one another and with applications via pub/sub (publisher/subscriber) systems.
B) A publisher is any device or application that sends a message to a cloud-based service, which in turn sends that message to all subscribers. Typically each publisher specifies a topic or channel, and each subscriber specifies one or more topics or channels for which they'd like to receive messages.
C) Apache Kafka is a Hadoop ecosystem component that provides a high-performance publish/subscribe service, real-time stream processing and storage of streamed data.
D) All of the above statements are true.
Unlock Deck
Unlock for access to all 79 flashcards in this deck.
Unlock Deck
k this deck
69
Which of the following statements reflect security, privacy and ethical concerns associated with IoT?
A) Unsecured IoT devices have been used to perform distributed-denial-of-service (DDOS) attacks on computer systems.
B) Home security cameras that you intend to protect your home could potentially be hacked to allow others access to the video stream.
C) Children have accidentally ordered products on Amazon by talking to Alexa devices, companies have created TV ads that would activate Google Home devices by speaking their trigger words and causing Google Assistant to read Wikipedia pages about a product to you. A judge recently ordered Amazon to turn over Alexa recordings for use in a criminal case.
D) All of the above statements reflect these concerns.
A) Unsecured IoT devices have been used to perform distributed-denial-of-service (DDOS) attacks on computer systems.
B) Home security cameras that you intend to protect your home could potentially be hacked to allow others access to the video stream.
C) Children have accidentally ordered products on Amazon by talking to Alexa devices, companies have created TV ads that would activate Google Home devices by speaking their trigger words and causing Google Assistant to read Wikipedia pages about a product to you. A judge recently ordered Amazon to turn over Alexa recordings for use in a criminal case.
D) All of the above statements reflect these concerns.
Unlock Deck
Unlock for access to all 79 flashcards in this deck.
Unlock Deck
k this deck
70
Which of the following statements a), b) or c) is false?
A) For Spark streaming, you must create a StreamingContext (from the module pyspark.streaming), providing as arguments the SparkContext and how often in seconds to process xe "Spark (Apache):batches of streaming data"xe "batch:of streaming data in Spark"batches of streaming data.
B) The following StreamingContext processes batches every 10 seconds-this is the xe "Spark (Apache):streaming batch interval"xe "batch:interval in Spark streaming"batch interval
Ssc = StreamingContext(sc, 10)
C) Depending on how fast data is arriving, you may wish to shorten or lengthen your batch intervals.
D) All of the above statements are true.
A) For Spark streaming, you must create a StreamingContext (from the module pyspark.streaming), providing as arguments the SparkContext and how often in seconds to process xe "Spark (Apache):batches of streaming data"xe "batch:of streaming data in Spark"batches of streaming data.
B) The following StreamingContext processes batches every 10 seconds-this is the xe "Spark (Apache):streaming batch interval"xe "batch:interval in Spark streaming"batch interval
Ssc = StreamingContext(sc, 10)
C) Depending on how fast data is arriving, you may wish to shorten or lengthen your batch intervals.
D) All of the above statements are true.
Unlock Deck
Unlock for access to all 79 flashcards in this deck.
Unlock Deck
k this deck
71
Which of the following statements a), b) or c) is false?
A) You work with a SparkContext using functional-style programming techniques (like filtering, mapping and reduction) applied to a resilient distributed dataset (RDD).
B) An RDD takes data stored throughout a cluster in the Hadoop file system and enables you to specify a series of processing steps to transform the data in the RDD.
C) The processing steps mentioned in Part (b) are greedy-the steps are performed immediately in response to the method call.
D) All of the above statements are true.
A) You work with a SparkContext using functional-style programming techniques (like filtering, mapping and reduction) applied to a resilient distributed dataset (RDD).
B) An RDD takes data stored throughout a cluster in the Hadoop file system and enables you to specify a series of processing steps to transform the data in the RDD.
C) The processing steps mentioned in Part (b) are greedy-the steps are performed immediately in response to the method call.
D) All of the above statements are true.
Unlock Deck
Unlock for access to all 79 flashcards in this deck.
Unlock Deck
k this deck
72
Which of the following statements is false?
A) A SparkContext (from module pyspark) object gives you access to Spark's capabilities in Python.
B) Many Spark environments create the SparkContext for you, but in the Jupyter pyspark-notebook Docker stack, you must create this object.
C) Threads enable a single node cluster to execute portions of the Spark tasks xe "concurrent execution"concurrently to simulate the parallelism that Spark clusters provide.
D) When we say that two tasks are operating in parallel, we mean that they're both making progress at once-typically by executing a task for a short burst of time, then allowing another task to execute. When we say that two tasks are operating concurrently, we mean that they're executing simultaneously, which is one of the key benefits of Hadoop and Spark executing on cloud-based clusters of computers.
A) A SparkContext (from module pyspark) object gives you access to Spark's capabilities in Python.
B) Many Spark environments create the SparkContext for you, but in the Jupyter pyspark-notebook Docker stack, you must create this object.
C) Threads enable a single node cluster to execute portions of the Spark tasks xe "concurrent execution"concurrently to simulate the parallelism that Spark clusters provide.
D) When we say that two tasks are operating in parallel, we mean that they're both making progress at once-typically by executing a task for a short burst of time, then allowing another task to execute. When we say that two tasks are operating concurrently, we mean that they're executing simultaneously, which is one of the key benefits of Hadoop and Spark executing on cloud-based clusters of computers.
Unlock Deck
Unlock for access to all 79 flashcards in this deck.
Unlock Deck
k this deck
73
Which of the following statements a), b) or c) is false?
A) PubNub is a pub/sub service geared to real-time applications in which any software and device connected to the Internet can communicate via small messages.
B) Some common PubNub use-cases include IoT, chat, online multiplayer games, social apps and collaborative apps.
C) PubNub provides several live streams for learning purposes, including one that simulates IoT sensors. One common use of live data streams is visualizing them for monitoring purposes.
D) All of the above statements are true.
A) PubNub is a pub/sub service geared to real-time applications in which any software and device connected to the Internet can communicate via small messages.
B) Some common PubNub use-cases include IoT, chat, online multiplayer games, social apps and collaborative apps.
C) PubNub provides several live streams for learning purposes, including one that simulates IoT sensors. One common use of live data streams is visualizing them for monitoring purposes.
D) All of the above statements are true.
Unlock Deck
Unlock for access to all 79 flashcards in this deck.
Unlock Deck
k this deck
74
Which of the following statements is false?
A) By default, Spark streaming maintains state information as you process the stream of RDDs.
B) You can use Spark checkpointing to keep track of the streaming state. Checkpointing enables xe "Spark (Apache):fault-tolerance in streaming"xe "fault tolerance:Spark streaming"fault-tolerance for restarting a stream in cases of cluster node or Spark application failures, and xe "Spark (Apache):stateful transformations in streaming"xe "stateful transformations (Spark streaming)"stateful transformations, such as summarizing the data received so far-as we're doing in this example.
C) StreamingContext method checkpoint sets up a checkpointing folder where state information is stored, as in: ssc.checkpoint('hashtagsummarizer_checkpoint')
D) For a Spark streaming application in a cloud-based cluster, you'd specify a location within xe "HDFS (Hadoop Distributed File System)"HDFS to store the checkpoint folder.
A) By default, Spark streaming maintains state information as you process the stream of RDDs.
B) You can use Spark checkpointing to keep track of the streaming state. Checkpointing enables xe "Spark (Apache):fault-tolerance in streaming"xe "fault tolerance:Spark streaming"fault-tolerance for restarting a stream in cases of cluster node or Spark application failures, and xe "Spark (Apache):stateful transformations in streaming"xe "stateful transformations (Spark streaming)"stateful transformations, such as summarizing the data received so far-as we're doing in this example.
C) StreamingContext method checkpoint sets up a checkpointing folder where state information is stored, as in: ssc.checkpoint('hashtagsummarizer_checkpoint')
D) For a Spark streaming application in a cloud-based cluster, you'd specify a location within xe "HDFS (Hadoop Distributed File System)"HDFS to store the checkpoint folder.
Unlock Deck
Unlock for access to all 79 flashcards in this deck.
Unlock Deck
k this deck
75
We created and ran a Spark streaming application which receives a stream of tweets on the topic(s) you specify and summarizes the top-20 hashtags in a bar chart that updates every 10 seconds. Which of the following statements a), b) or c) is false?
A) One way for Spark streaming to receive data is via a network socket-a low-level view of xe "client/server networking"client/server networking in which a xe "client/server app:client"xe "client/server app:client¶"client app communicates with a xe "client/server app:server"xe "server in a client/server app"server app over a network.
B) Each xe "socket"socket represents one xe "endpoint:of a connection"endpoint of a connection.
C) A program can read from a socket or write to a socket similarly to reading from or writing to a SQL database.
D) All of the above statements are true.
A) One way for Spark streaming to receive data is via a network socket-a low-level view of xe "client/server networking"client/server networking in which a xe "client/server app:client"xe "client/server app:client¶"client app communicates with a xe "client/server app:server"xe "server in a client/server app"server app over a network.
B) Each xe "socket"socket represents one xe "endpoint:of a connection"endpoint of a connection.
C) A program can read from a socket or write to a socket similarly to reading from or writing to a SQL database.
D) All of the above statements are true.
Unlock Deck
Unlock for access to all 79 flashcards in this deck.
Unlock Deck
k this deck
76
The PubNub client uses a ________ key in combination with a channel name to subscribe to a channel.
A) signature
B) subscription
C) connection
D) None of the above
A) signature
B) subscription
C) connection
D) None of the above
Unlock Deck
Unlock for access to all 79 flashcards in this deck.
Unlock Deck
k this deck
77
To query a Spark DataFrame, you must first create a xe "Spark (Apache):table view of a DataFrame"xe "table view of a Spark DataFrame"table view, which enables Spark SQL to query the DataFrame like a table in a ________ database.
A) hierarchical
B) graph
C) key-value
D) relational
A) hierarchical
B) graph
C) key-value
D) relational
Unlock Deck
Unlock for access to all 79 flashcards in this deck.
Unlock Deck
k this deck
78
Which of the following statements a), b) or c) is false?
A) You can publish periodic JSON messages-called xe "dweet (message in dweet.io)"dweets-for free to dweet.io.
B) The name "dweet" is based on "tweet"-a dweet is like a tweet, but from from a device rather than a person.
C) By default, dweet.io is a public service, so any app can publish or subscribe to messages.
D) All of the above statements are true.
A) You can publish periodic JSON messages-called xe "dweet (message in dweet.io)"dweets-for free to dweet.io.
B) The name "dweet" is based on "tweet"-a dweet is like a tweet, but from from a device rather than a person.
C) By default, dweet.io is a public service, so any app can publish or subscribe to messages.
D) All of the above statements are true.
Unlock Deck
Unlock for access to all 79 flashcards in this deck.
Unlock Deck
k this deck
79
PubNub provides the ________ Python module for conveniently performing pub/sub operations.
A) pubsub
B) pubnub
C) subpub
D) None of the above.
A) pubsub
B) pubnub
C) subpub
D) None of the above.
Unlock Deck
Unlock for access to all 79 flashcards in this deck.
Unlock Deck
k this deck
Unlock Deck
Unlock for access to all 79 flashcards in this deck.



