In a Monte Carlo study, econometricians generate multiple sample regression functions from a known population regression function. For example, the population regression function could be Yi = ?0 + ?1Xi = 100 - 0.5 Xi. The Xs could be generated randomly or, for simplicity, be nonrandom ("fixed over repeated samples"). If we had ten of these Xs, say, and generated twenty Ys, we would obviously always have all observations on a straight line, and the least squares formulae would always return values of 100 and 0.5 numerically. However, if we added an error term, where the errors would be drawn randomly from a normal distribution, say, then the OLS formulae would give us estimates that differed from the population regression function values. Assume you did just that and recorded the values for the slope and the intercept. Then you did the same experiment again (each one of these is called a "replication"). And so forth. After 1,000 replications, you plot the 1,000 intercepts and slopes, and list their summary statistics.
Here are the corresponding graphs: 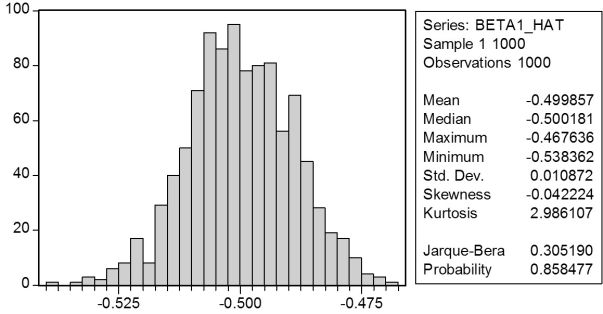
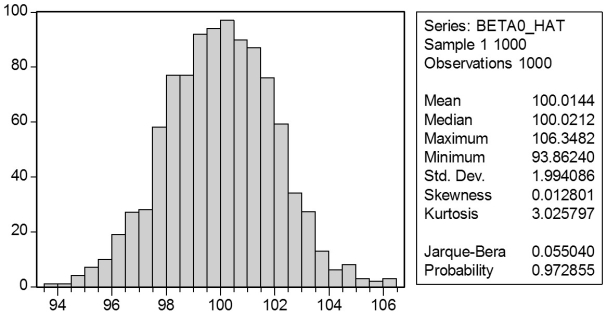 Using the means listed next to the graphs, you see that the averages are not exactly 100 and -0.5. However, they are "close." Test for the difference of these averages from the population values to be statistically significant.
Using the means listed next to the graphs, you see that the averages are not exactly 100 and -0.5. However, they are "close." Test for the difference of these averages from the population values to be statistically significant.
Correct Answer:
Verified
View Answer
Unlock this answer now
Get Access to more Verified Answers free of charge
Q42: Using the California School data set
Q43: In many of the cases discussed in
Q44: Using data from the Current Population Survey,
Q45: Assume that the homoskedastic normal regression assumption
Q46: Using the California School data set
Q48: The neoclassical growth model predicts that
Q49: Your textbook discussed the regression model
Q50: (Requires Appendix material and Calculus)Equation (5.36)in
Q51: Consider the following two models involving
Q52: Assume that your population regression function is
Yi
Unlock this Answer For Free Now!
View this answer and more for free by performing one of the following actions

Scan the QR code to install the App and get 2 free unlocks

Unlock quizzes for free by uploading documents